
Train Better Models, Faster
State-of-art Pretraining, Fine-tuning and Distillation for Computer Vision Models. Get started in less than 5 minutes.
Trusted by entreprises, researchers and startups.






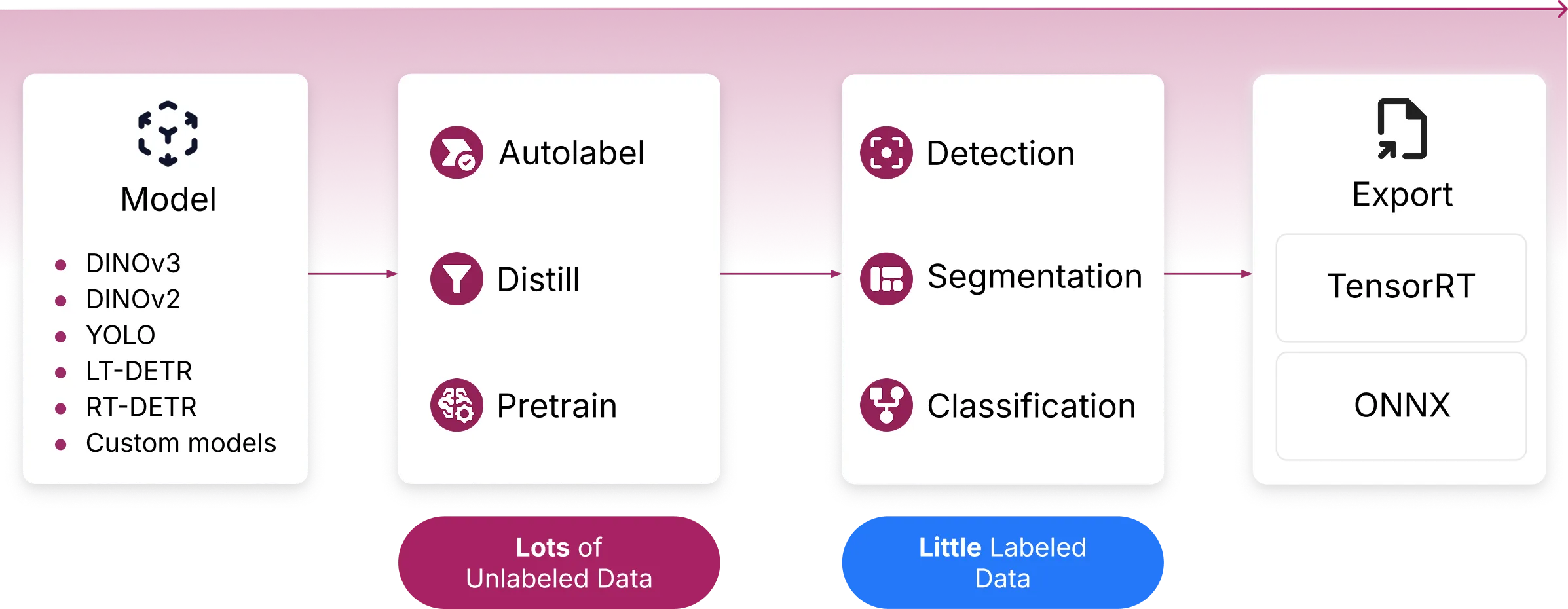
How LightlyTrain Works
Pretraining
Pretrain
Pretrain DINOv2 foundation models on your domain data.

Autolabel

Generate high-quality pseudo labels for detection and segmentation tasks

Distill

DIstill knowledge from DINOv2 or DINOv3 into any model architecture.

Fine-tuning
Detection

Train LTDETR detection models with DINOv2 or DINOv3 backbones.

Segmentation

Train EoMT segmentation models with DINOv3 backbones

Classification

Train image classification models with any backbone

How LightlyTrain fits into your ML stack
Experience the LightlyTrain Difference
Without LightlyTrain



With LightlyTrain

Say Goodbye to Labels, Hello to Better Models
For Real-World Applications
Purpose-built for real-world computer vision tasks in video analytics, agriculture, manufacturing, retail, and more.

Up to 36% Higher mAP
Achieve better performance compared
to traditional supervised learning approaches.
Model & Tasks Agnostic
Works with multiple CV tasks: object detection, classification, segmentation and more.
How to Get Started From Data to Model in 3 Steps

Install LightlyTrain
Quickly install LightlyTrain with a single command to get started.
1

Run pretraining
Use your dataset to pretrain a model with just a few lines of code.
2

Fine-tune your model
Load your pretrained weights and fine-tune them for your specific task.
3
License
Ready to Get Started?
Join 100+ ML teams that have cut their training costs by more than 50% with Lightly products.
Book a Demo




