
Embeddings in Machine Learning: An Overview
Table of contents
Share blog post



Embeddings are vector representations that encode the meaning and relationships of data like words or images. They map items into continuous spaces where similar entities are close, powering NLP, vision, and recommendation systems.
Share blog post
Here is an overview of embedding spaces and their role in multi-modal learning:
What are embeddings in AI?
Embeddings are dense numerical vectors - lists of floating point numbers - that represent real-world objects in a continuous vector space. A machine learning model uses embeddings to process and compare text, images, audio signals, or graph nodes mathematically. Embeddings place similar objects close together in that space, making it simple for ml algorithms to find related content and compare similar objects.
What is the meaning of embedding?
An embedding is a fixed-length numerical representation of an object as an embedding vector in a multi-dimensional space. The term describes the act of "embedding" high-dimensional or categorical data into lower dimensional representations where determining similarity between two vectors becomes a simple distance calculation. Text embeddings, image embeddings, and graph embeddings are all instances of this idea applied to different data types.
What is an example of embedding?
A simple version: Word2Vec assigns each word in a corpus an embedding vector of floating point numbers. Words appearing in similar contexts end up with similar embeddings. The classic demonstration: the embedding for "king" minus "man" plus "woman" points near the embedding for "queen." Text embeddings extend this to full sentences and documents, enabling tasks like semantic search and sentiment analysis.
What are embeddings in ChatGPT?
Large language models like ChatGPT use embeddings at every stage. Input tokens are first converted into embeddings, then passed through multiple hidden layers of transformer attention. These embeddings capture contextual relationships between all the words in a sequence, enabling the model to produce contextually relevant responses to user queries.
Machine learning algorithms operate on numerical data. They cannot read raw text, parse images, or analyze audio signals directly. Embeddings bridge that gap by converting real-world objects into dense numerical vectors that ml algorithms can process, compare, and learn from.
In this guide, we cover:
- What embeddings are and how they work
- Why embeddings matter for machine learning
- How embeddings are created and trained
- Types of embeddings: text, image, graph, and more
- Applications of embeddings including retrieval, recommendation pipelines, and RAG
Embeddings are only as good as the data behind them. LightlyStudio helps ML engineers curate the most representative datasets for training embedding models, while LightlyTrain enables self-supervised pretraining to produce high-quality domain-specific embeddings without requiring labels.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Part 1: What Are Embeddings in Machine Learning?
Embeddings are dense vector representations of data in a continuous vector space. They map high-dimensional or categorical inputs - a word, an image, a user profile - into a compact list of numbers while preserving semantic meaning and the semantic relationships between them.
The alternative is a sparse vector. One-hot encoding represents each word as a sparse vector with a single 1 and zeros everywhere else. These sparse representations scale poorly: a vocabulary of 100,000 words produces a vector with 100,000 dimensions, almost all empty. Embeddings compress the same word into a dense vector of 100-1,000 values that encode actual meaning.
Embeddings work by placing similar objects close together in the embedding space. A machine learning model trained on your data learns to position semantically related items nearby - words with related meanings, images with similar visual content, or users with overlapping behavior. This geometric structure is what makes embeddings powerful across so many machine learning tasks.
For example, in the image below, the vectors for cat and kitten, or adult and child, are close together in the embedding space because of their semantic similarity. And, if there is a vector for a car, it would be far apart due to dissimilarity.
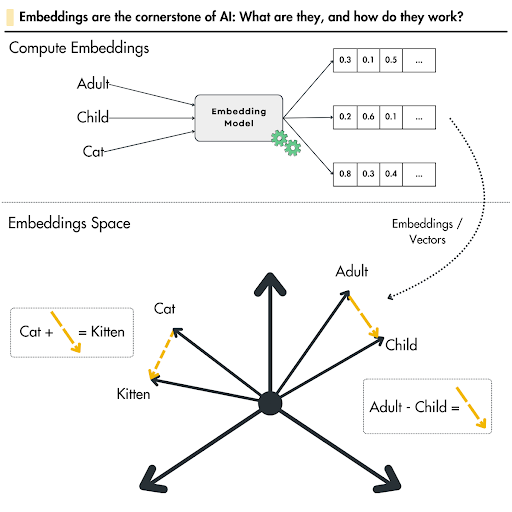
Why Embeddings Matter: Benefits and Importance
Capturing Semantic Relationships
Embeddings capture the semantic relationships between objects in a way that sparse or hand-crafted features cannot. The distances between embedding vectors in the embedding space reflect real-world similarity. A machine learning model can determine that "doctor" and "physician" are near-synonyms simply because their embeddings are close - without any explicit rules.
Dimensionality Reduction
High dimensional data is expensive to process. Embeddings compress high dimensional vectors into lower dimensional representations, filtering out noise while retaining the structure a machine learning model needs. Principal components and similar compression techniques informed early approaches; modern neural networks learn these lower dimensional representations directly from data.
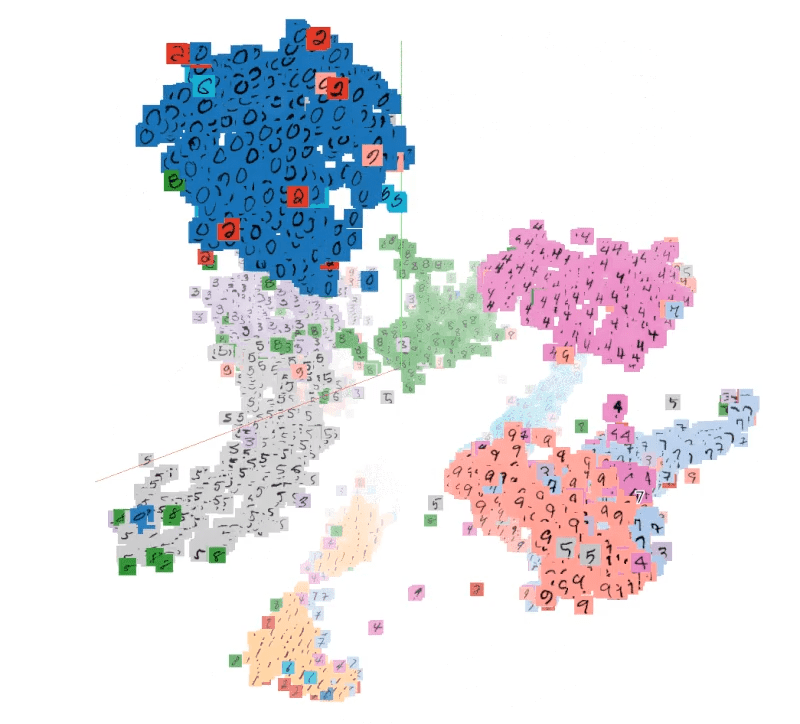
Enabling Similarity Searches
Because embeddings place similar objects close together, they are the foundation for similarity searches at scale. Determining similarity between two vectors is a single calculation: cosine similarity or Euclidean distance between the embedding vectors of a query and each candidate. The closer two embeddings are in the embedding space, the more similar the objects they represent. This principle applies to text similarity, image retrieval, and product search alike.
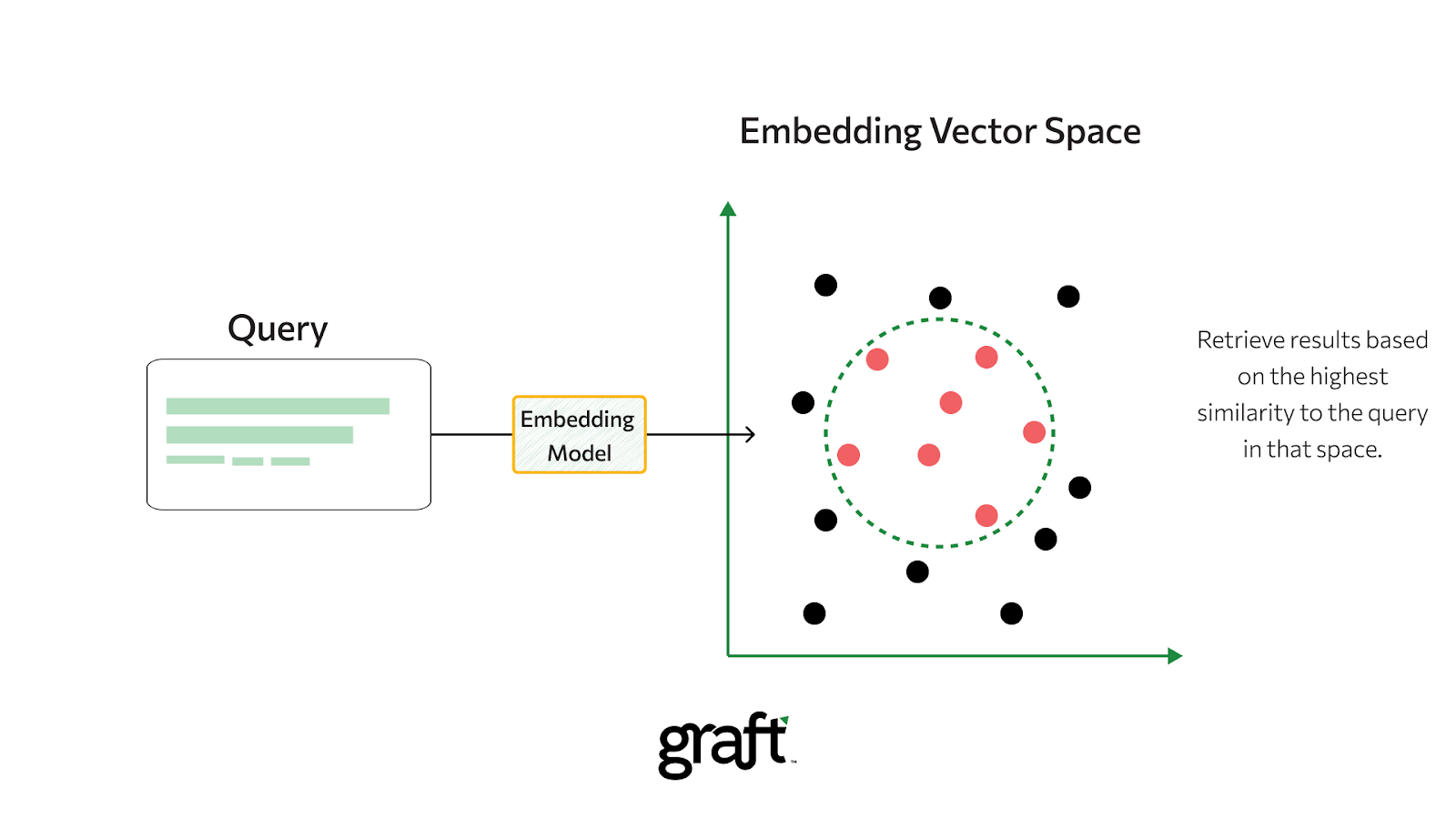
Improved Generalization
Embeddings allow a machine learning model to generalize across related inputs it has never seen together. If two words share similar neighboring words in training data, their embeddings end up close - even if they never appeared in the same sentence. This property makes embedding-based machine learning models robust to gaps in training data.
How Are Embeddings Created?
Embeddings are created through a process called embedding learning, in which a model learns to map inputs to vectors that preserve meaningful patterns. There are three main approaches.
Using an Embedding Layer
The most direct method is to include an embedding layer in neural networks. This layer is a trainable matrix that acts as a lookup table mapping discrete inputs to embedding vectors. When neural networks receive a word ID or item ID, they retrieve the corresponding embedding from this table.
Initially, embeddings are random. As training progresses through hidden layers, the network updates embeddings to minimize prediction error. Over time, the embedding layer learns to assign similar vectors to items that behave similarly - producing meaningful embeddings without explicit supervision.
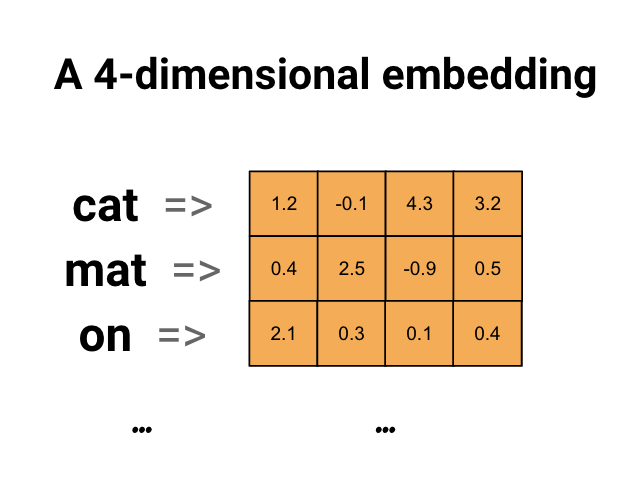
Using Pretrained Embedding Models
Most teams start with pretrained embedding models that have already learned rich representations from large datasets. A pretrained embedding model saves training time and typically produces stronger embeddings than training from scratch on limited data.
- For text: OpenAI's text-embedding-3-large and Alibaba's Qwen3-Embedding-8B generate embeddings for semantic search and RAG. These embedding models support Matryoshka Representation Learning (MRL), which lets developers shorten embeddings by removing numbers from the end of the embedding vector without losing their concept-representing properties - enabling flexible usage across different storage or computational constraints.
- For images: Pretrained CNNs like ResNet and Vision Transformers (ViTs) create embeddings for image classification and object detection.
- For multimodal data: Google's Gemini Embedding 2 maps text, images, video, and audio into a single shared embedding space.
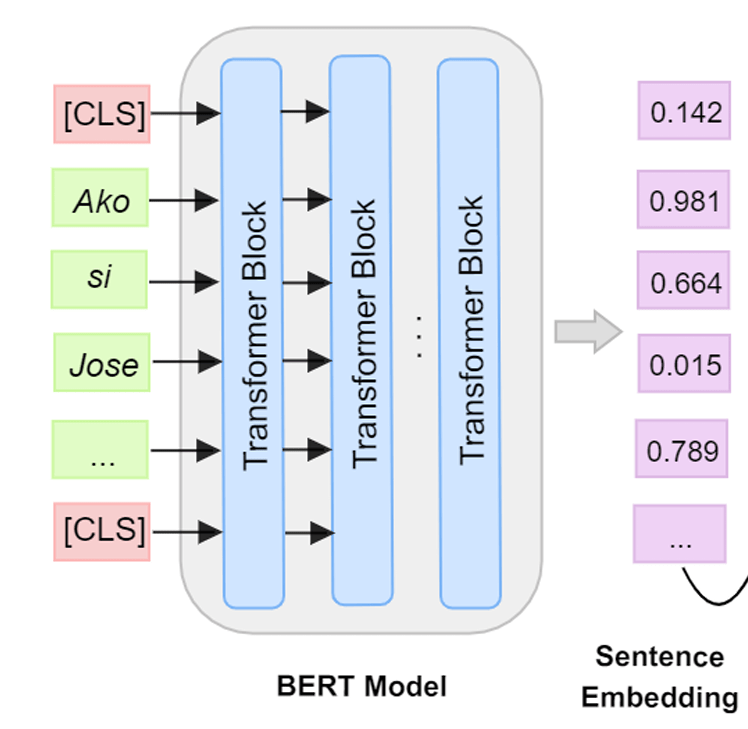
Using Self-Supervised Learning
When pretrained embedding models do not match your domain - medical images, industrial inspection, or satellite data - self-supervised learning lets you create embeddings from unlabeled data by using the structure of the data itself as supervision.
Key methods to generate embeddings through self-supervised learning include:
Contrastive Learning (SimCLR, MoCo): embeddings from two augmented views of the same image are pulled together in the embedding space, while embeddings from different images are pushed apart.
Word2Vec: a model developed by Google that creates word embeddings by training neural networks to predict the target word from its context (CBOW) or neighboring words from the target word (Skip-gram). The result: word embeddings that encode semantic nuances across the full vocabulary in a corpus.
GloVe: a statistical method that builds a global co-occurrence matrix across word counts in a corpus and applies singular value decomposition to factorize it, producing word embeddings that capture global statistical patterns. This is conceptually related to latent semantic analysis (LSA), an earlier statistical method that also uses singular value decomposition on a term-document matrix to extract latent features and create lower dimensional representations of text data.
LightlyTrain makes it simple to create embeddings with self-supervised learning on your domain data:
import lightly_train
if __name__ == "__main__":
lightly_train.train(
out="out/my_experiment",
data="my_data_dir",
model="torchvision/resnet18",
method="simclr",
)LightlyTrain supports DINOv3, SimCLR, DINO, YOLO (v8, v11), RT-DETR, ViTs, ResNet, and Faster R-CNN.
Part 2: Types of Embeddings
Word Embeddings and Text Embeddings
Word embeddings represent individual words as dense vectors based on their usage patterns in a language corpus. Models like Word2Vec and GloVe produce static word embeddings: each word receives one fixed embedding regardless of context. Word embeddings capture semantic relationships and contextual meanings of words, represented as fixed-size dense vectors of real numbers - enabling models to learn that "cat" and "feline" refer to similar objects.
Text embeddings extend word embeddings to represent entire sentences, paragraphs, or documents as a single embedding vector. Text embeddings play a crucial role in NLP applications: they power semantic search, text similarity scoring, sentiment analysis, document clustering, and RAG retrieval pipelines. Modern transformer-based models produce contextual text embeddings where the same word receives different embeddings depending on the surrounding sentence - allowing text embeddings to capture ambiguity and nuance that static word embeddings miss.

Image Embeddings
Image embeddings capture the visual features and semantic information of an image - colors, textures, shapes, and high-level object content - in one compact vector. A machine learning model extracts image embeddings from the final hidden layers of a pretrained CNN or ViT.
Image embeddings enable image classification and object detection by providing rich visual features for downstream models to learn from. DINOv3 (2025) represents the current state of the art in self-supervised image embeddings, with a 7-billion-parameter backbone that produces image embeddings transferring strongly across image classification and object detection tasks.
Graph Embeddings
This embedding approach maps nodes and edges of a network into a vector space, preserving the graph's structural relationships. Methods like DeepWalk and node2vec generate embeddings by running random walks on the graph and training Word2Vec-style neural networks on those walks.
These node embeddings are essential for tasks like node classification and link prediction in complex networks. Applications span social network analysis, knowledge graphs, and fraud detection - anywhere the relationships between entities carry as much meaning as the entities themselves.

Audio and Categorical Embeddings
Audio embeddings are generated using deep learning architectures that capture relevant features of audio data for applications like speech recognition and music analysis. Models like Wav2Vec learn audio embeddings directly from raw audio signals.
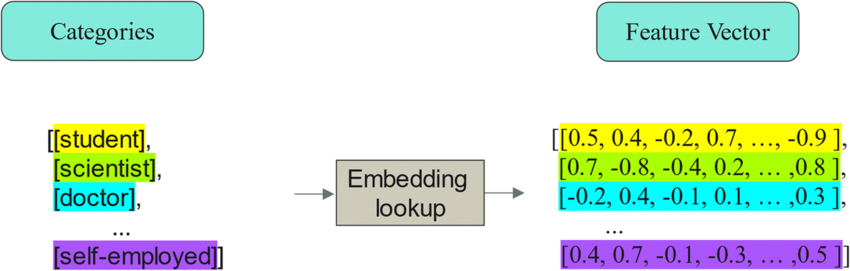
For categorical data, embedding layers replace one-hot encoding. Rather than one-hot encoding with a single nonzero value, each category gets a compact embedding that the ml model learns to position meaningfully in the embedding space, enabling models to discover similarity between categories from training data alone.
Applications of Embeddings in Machine Learning
Semantic Similarity Searches and Vector Databases
Embeddings are the foundation of modern similarity searches. A query and all candidate items are converted to embeddings; the system retrieves the candidates whose embedding vectors are closest to the query embedding vector. Cosine similarity and Euclidean distance are the two standard metrics for measuring distance between embedding vectors.
Vector databases - Qdrant, Milvus, Pinecone, and Weaviate - store and index these embeddings to enable high-throughput similarity searches across millions or billions of items. Semantic search uses embeddings to find results based on meaning rather than keyword matching, and multimodal AI models map text and images into the same embedding space to enable similarity searches using text descriptions to find images.
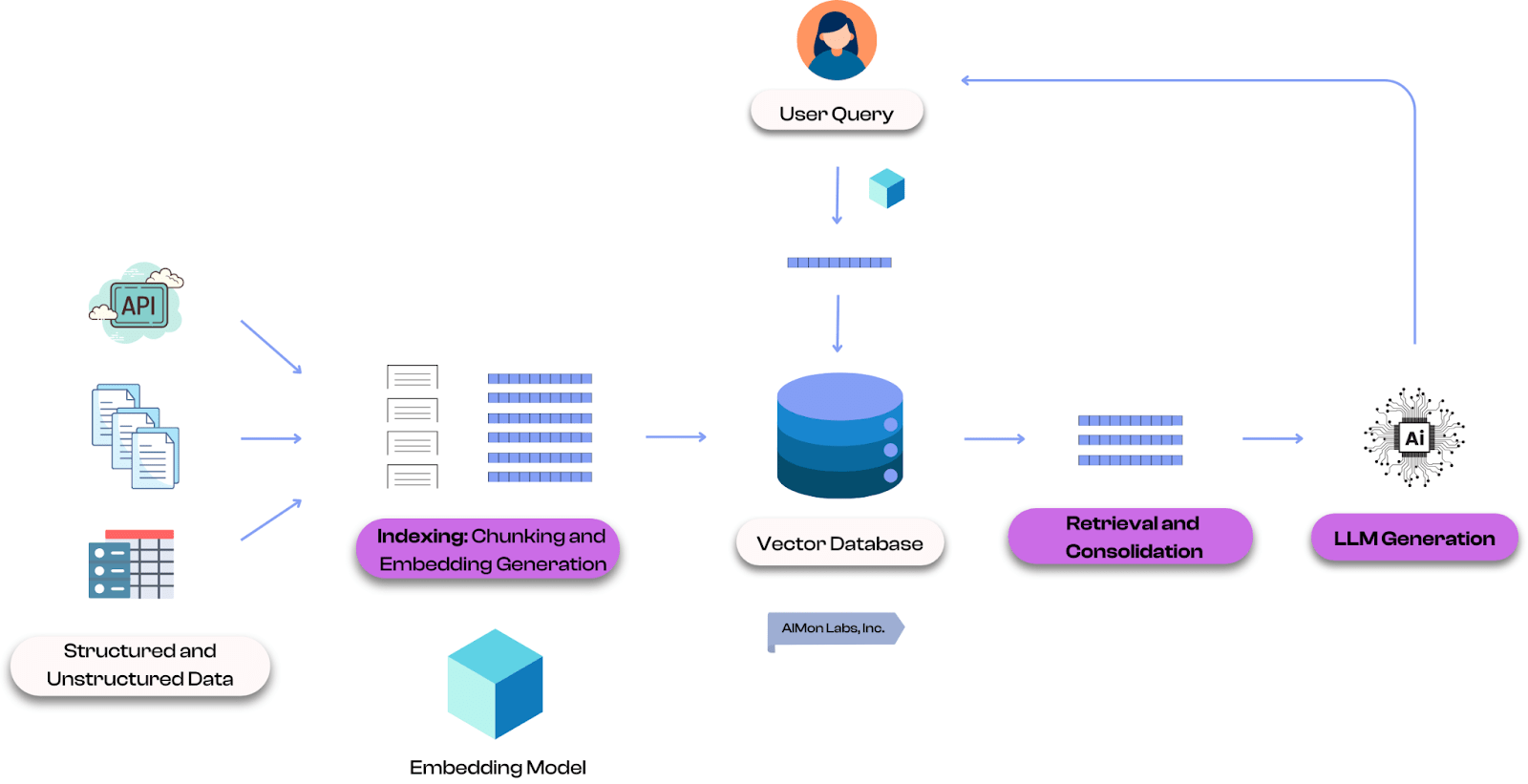
Retrieval-Augmented Generation (RAG) in Large Language Models
Large language models have a fixed knowledge cutoff and can produce incorrect answers for facts they were not trained on. RAG addresses this by retrieving relevant text embeddings at inference time. A user's query is converted to an embedding, the most similar text embeddings in a knowledge base are retrieved, and those passages are given to the model as context - producing contextually relevant responses grounded in up-to-date information.
Recommender Systems
Recommender systems create embeddings to represent users and items in a shared vector space. To reflect users' preferences, the system finds items whose embeddings are closest to the user's embedding and surfaces those as recommendations. Represent users accurately in the embedding space and the system can identify preferences from behavior alone, without explicit ratings.
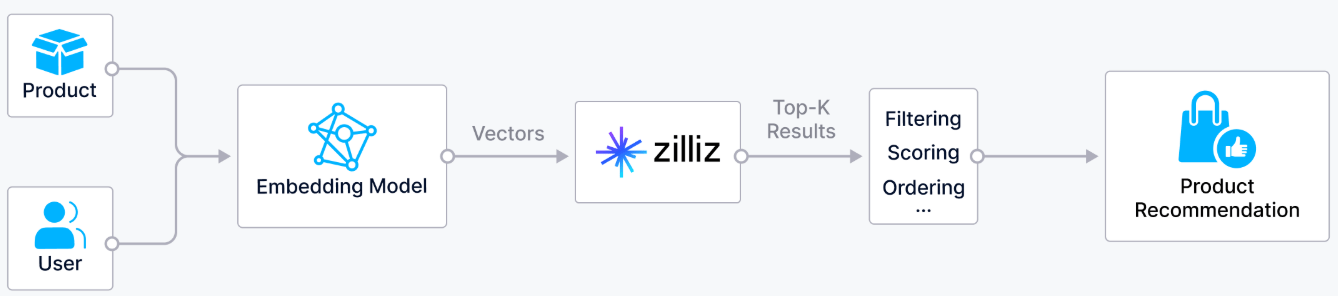
Fraud Detection
In banking, transaction embeddings encode the behavioral patterns of each account. Fraud detection systems identify outliers by finding transactions whose embedding vectors are far from the user's normal embedding cluster. Embeddings enable fraud detection to catch unusual behavior even when no explicit rule defines what fraud looks like - the anomaly shows up as a distance in the embedding space.
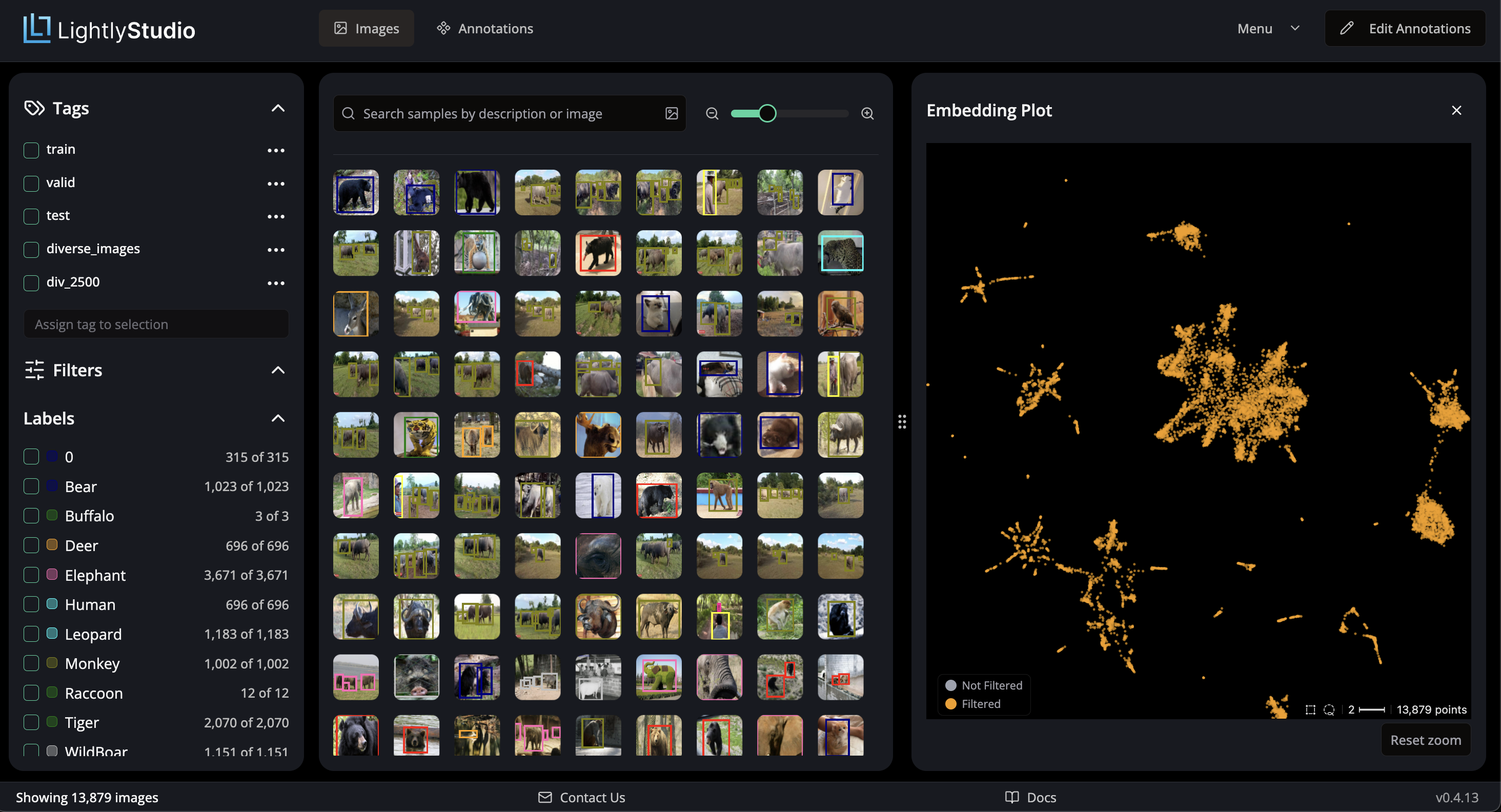
Active Learning and Data Curation
Real datasets often contain many near-duplicate samples. Active learning uses embeddings to select the most informative subset for labeling. Diversity sampling clusters unlabeled data by embeddings, then selects representative samples from each cluster - ensuring labeled training data covers meaningful variation.
LightlyStudio automates this workflow with its DIVERSITY strategy:
config = {
"strategies": [
{
"input": {
"type": "EMBEDDINGS",
},
"strategy": {
"type": "DIVERSITY",
"stopping_condition_minimum_distance": 0.2,
},
}
]
}Best Practices for Using Embeddings
Match the embedding model to your data and task. Use text embeddings for natural language processing, image embeddings for visual data, and graph embeddings for network data. When working with high dimensional domain-specific data, a custom embedding model trained with self-supervised learning typically outperforms general-purpose pretrained embedding models.
Choose the right dimensionality. The specified dimension of an embedding vector is a trade-off: more dimensions capture more detail but increase storage and compute costs. Using larger embeddings generally costs more compute, memory, and storage than using smaller embeddings. MRL-capable embedding models let you shorten embeddings at inference time with minimal quality loss.
Normalize embedding vectors before similarity searches. Normalizing embeddings to unit length lets you use the dot product rather than full cosine similarity, reducing compute for large-scale similarity searches across two vectors.
Audit for bias. Embeddings learn from training data and can amplify biases present in it. LightlyStudio's embedding-based data selection helps ensure training data covers all meaningful scenarios without over-representing easy or redundant examples.
How Can Lightly AI Help?
High-quality embeddings depend on both the embedding model and the training data. LightlyStudio is a unified platform for curating and labeling image and video datasets - with embedding-based data selection, near-duplicate detection, active learning, built-in annotation, QA, and a Python-first SDK. It ensures your training data is diverse and representative before any model training begins, with on-prem deployment and enterprise user management.
LightlyTrain handles the pretraining side. It uses self-supervised learning to generate embeddings from unlabeled domain data - no labels required. By learning the specific visual patterns of your domain first, LightlyTrain produces image embeddings that generalize better to downstream tasks like image classification and object detection. It supports DINOv3, SimCLR, DINO, YOLO, RT-DETR, and ResNet.
Conclusion
Embeddings convert complex real-world data into the numerical language that machine learning models can reason over. By positioning similar objects close together in a continuous vector space, embeddings power search and retrieval, large language models, recommender systems, fraud detection, and active learning - across text, visual data, audio signals, and graph domains.
As embedding models grow more capable and techniques like MRL make them more efficient to deploy at scale, embeddings will remain foundational to how ML systems understand and compare information. Good embeddings start with good data and the right embedding model for your domain.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.

.png)
.png)
.png)


