
LightlyOne 3.0: New Typicality-Based Selection, 6x Speedup, and Better Scalability
Table of contents
Share blog post



LightlyOne 3.0 introduces a rebuilt core for up to 6x faster performance, lower memory use, and better scalability. It features a typicality-based selection method, supports user predictions, local storage, and a cleaner UI.
Share blog post
Smarter selection, faster performance, broader support A look at what’s new in LightlyOne 3.0 and how it reshapes the experience.
- Up to 6x faster and 70% lower memory usage thanks to a rebuilt core architecture.
- New typicality-based selection method for smarter, more representative sampling.
- Bring your own predictions to guide selection based on your model’s outputs.
- Runs anywhere – now with local storage support and full ARM compatibility.
- New correlation view for exploring patterns in your data and model outputs.
- Improved UI with better filtering, dataset slicing, and support for up to 500k images.
You’ll notice a faster, more flexible, and smarter experience across the board. Dive into the docs or try it out today.
If you tried LightlyOne in the past, we recommend taking another look.
Over the last one to two years, we’ve rethought and rebuilt core components of LightlyOne. Version 3.0 is now available, representing a significant step forward. It brings substantial improvements in speed, lower memory usage, and enhanced scalability, alongside new algorithms and an improved user experience.
For those who haven't purchased a license yet, this is a good opportunity to re-evaluate it :) Check out the LightlyOne documentation or book a meeting with our team to learn more.

Core Performance Upgrades
A key change in LightlyOne 3.0 is its improved performance.
We profiled core pipelines, redesigned memory-heavy sections, and implemented new parallelization strategies. These architectural changes have led to major improvements:
- Up to 6x Faster*: Experience faster end-to-end processing and API responsiveness.
- Over 70% Lower Peak Memory Usage*: This large reduction enables more parallelism and stability.
- Improved Scalability*: Scales efficiently across >40 physical CPU cores and adapts from cloud instances to local notebooks.
*Internal benchmarks on various datasets consisting of image data or video data compared against version 2.0
How we Boosted the Performance
We examined every aspect of LightlyOne that makes it a great and valuable technology for our customers and challenged ourselves to go beyond. Each operation in the pipeline was carefully analyzed to identify bottlenecks caused by network bandwidth, latency, CPU compute, memory bandwidth, GPU usage, general overhead, or inefficient CPU clocks.
We added concurrency where necessary and split operations into different processes where possible, significantly lowering peak memory consumption through pickling and by smartly adapting to the customer's machine setup.
The entire architecture was reworked to enhance UX and error handling. An optimized listing engine was also developed, designed to scale horizontally with client needs.
Additionally, we diligently examined external dependencies to see how they affected us. For an example, see our separate blog post about getting a 2x speedup in dataloading from replacing Pillow with Albumentations.

More Flexible Infrastructure Support
LightlyOne 3.0 adapts to your environment:
- Local Storage Integration: You can now mount a local file system directly without the need of first uploading your data to the cloud. If you have a fast local disk, this can provide a significant speedup for your workflows.
- ARM Support: Our LightlyOne Worker which securely runs as a docker container is now compatible with ARM-based CPU. This includes Apple Silicon (M1/M2/M3) and ARM cloud instances.
- Adaptive Scalability: Whether you're working on a notebook with a few cores or on machines with nearly 100 virtual cores, LightlyOne 3.0 adapts to your available resources.
This flexibility makes LightlyOne 3.0 effective for both local development and production workloads.
New Features
We’ve also added new capabilities to make LightlyOne even more powerful.
Introducing: Typicality-Based Selection
We've introduced a new data selection method: typicality-based selection.
Many are familiar with our diversity-based selection, which picks dissimilar samples from an embedding space. However, this approach can overlook the density of your data – how "typical" or representative a sample is within its local neighborhood.
Typicality-based selection addresses this by balancing:
- Density Awareness: Ensuring that dense clusters of common patterns are represented appropriately, helping to preserve the underlying structure of your data.
- Diversity: Ensuring a wide range of examples common to your dataset.
This is especially useful when:
- Selecting a small subset from a large dataset.
- Working with imbalanced distributions.
- Needing to preserve the overall statistical properties of your original data in your selection.
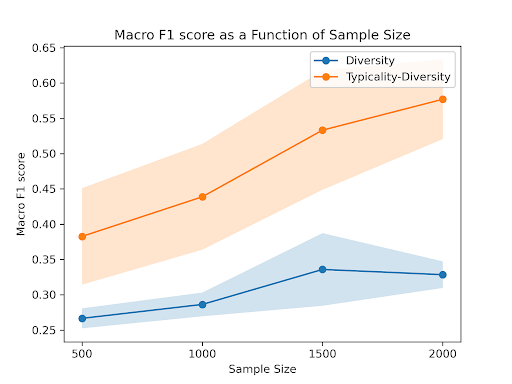
Plot from our blog post about how to select the most typical samples. The plot shows how using typicality alongside diversity improves the model accuracy when trained on a very small fraction of the cifar10 dataset.
This method has shown good results. You can learn more about how to select the most typical samples in our blog.
Bring Your Own Predictions
LightlyOne can now select images based on your model predictions with our object detection workflows. This enables you to select images given a wide range of criteria such as balancing the class distribution of your objects, considering the amount of detected objects in your images, or finding images with the most diverse objects. And if you don’t have a model yet, you can simply use our pretagging feature to start with a baseline.
Using this feature additionally unlocks valuable insights into your model predictions within the LightlyOne Platform, allowing you to e.g. easily select and export objects with a low confidence score, and finding clusters of outliers within a class.

Correlation View
Vision datasets hold a wealth of metadata, enhanced by your own additions and coupled with automatically extracted information by LightlyOne. This wealth of information can be challenging to access. However, the correlation view allows for unlocking and exploring this data. Users can plot and analyze it by freely configuring the X and Y axes, and project additional insights onto the scatter plot.
This capability empowers the discovery of hidden correlations and the uncovering of previously unseen relationships within the dataset e.g. correlate model confidence scores of large objects with sharpness or their class.

UI & User Experience: Improved Clarity and Scale
You’ll also find additional exciting improvements in the LightlyOne Platform:
- New Filtering Capabilities: Easily combine multiple filters to unlock new insights by Ie. filter your dataset by the total number of object detections, that are blurry and were made by a specific camera.
- Dataset Slicing: Segment your datasets to visually explore subsets.
- Increased Viewing Limits: You can now visualize and interact with up to 500,000 images in the UI at once (up from 250,000 in the previous version).
- Share data with your Team: Easily share datasets with your team
- General Polish: Expect faster rendering, smoother filtering, and bug fixes that contribute to a better user experience.
These improvements, along with updates to our documentation and onboarding flows, are designed to help your team work with large-scale datasets more effectively.
What’s Next for LightlyOne?
LightlyOne 3.0 is a significant improvement, and we plan to continue enhancing it. Our focus for the near future includes:
- Smarter Selection: We’re exploring active learning techniques and hybrid selection strategies to help you pinpoint valuable data more precisely.
- Improved Embeddings: We plan to roll out continuous improvements to our embedding models.
- Continued Speed Optimizations: We will continue to optimize performance.
Try LightlyOne 3.0 Today
LightlyOne 3.0 is available now. If you're an existing user, upgrading is straightforward. If you’re new to LightlyOne, or if you evaluated us in the past, now is a good time to see the improvements.
Learn how LightlyOne 3.0 can improve your data curation workflows:
We're pleased to release LightlyOne 3.0 and look forward to seeing what you build with it.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.

-min.png)
-min.png)
-min.png)


