
Introducing LightlyTrain: Better Vision Models, Faster - No Labels Needed
Table of contents
Share blog post



LightlyTrain lets you pretrain vision models on your own unlabeled data — no labels needed. Improve performance on classification, detection, and segmentation tasks while reducing labeling costs and speeding up deployment. Compatible with popular architectures like YOLO, RT-DETR, and ResNet, LightlyTrain adapts models to your domain and integrates easily into existing pipelines — fully on-premise and scalable to millions of images.
Share blog post
Here is some key information about LightlyTrain.
- What is LightlyTrain?
LightlyTrain is a solution that enables foundation models to work effectively on your specific data. It's a self-supervised pretraining framework designed for industrial applications, allowing teams to pretrain models on their own unlabeled data.
- Why is pretraining on your own data important?
While general pretrained models exist, they often struggle with domain-specific data. LightlyTrain bridges this gap by letting you pretrain models on your unique unlabeled data, leading to substantial performance gains in classification, detection, and segmentation tasks.
- What are the key benefits of using LightlyTrain?
No Labels Required: Accelerate development by pretraining models on unlabeled image and video data.
Domain Adaptation: Improve models by pretraining on your specific domain data (e.g., automotive, healthcare, agriculture).
Model & Task Agnostic: Compatible with a wide range of architectures (YOLO, ResNet, Vision Transformers) and tasks (detection, classification, segmentation).
Industrial-Scale Support: Scales from thousands to millions of images and supports on-premise, cloud, single, and multi-GPU setups.
Reduced Labeling Costs & Faster Deployment: Significantly reduces the amount of labeling needed, saving costs and speeding up model deployment.
- How does LightlyTrain compare to other pretraining methods?
Models pretrained with LightlyTrain consistently achieve higher performance than both ImageNet pretrained models and models trained from scratch. Benchmarks show significant improvements across different model architectures (like YOLO series, RT-DETR, Faster R-CNN) and dataset sizes, especially when labeled data is scarce.
We are excited to announce LightlyTrain: A solution which makes foundation models work on your data.
Pretrained models have allowed huge breakthroughs in many computer vision applications. However, they are trained on generic datasets like ImageNet or COCO. This limits their effectiveness in domain specific applications.
LightlyTrain bridges this gap and unlocks the potential of foundation models pretrained on your data. Our self-supervised pretraining framework is tailored for industrial applications. With LightlyTrain, teams can pretrain models on unlabeled data from their own domain, and see substantial gains in performance across classification, detection, and segmentation tasks.
Models pretrained with LightlyTrain achieve consistently higher performance across different model architectures and dataset sizes – outperforming both ImageNet and models trained from scratch.

Bringing Pretraining to Industry
Pretraining on your own data works. We already built one of the most widely used self-supervised learning frameworks for research. But industry adoption was difficult: the expertise necessary to make pretraining work made it inaccessible. Therefore, we set out to make pretraining easy. LightlyTrain is the result of many iterations with our clients: we abstracted away the nitty gritty details and focused on what they really cared about: a simple way to train better models.
Why LightlyTrain?
LightlyTrain helps industry clients unlock the potential of foundation models on domain-specific tasks. By pretraining a model on your unlabeled, domain-specific data, you significantly reduce the amount of labeling needed to reach a high model performance. Therefore, LightlyTrain reduces labeling costs and speeds up model deployment.
This allows you to focus on new features and new domains instead of managing your labeling cycles. LightlyTrain is designed for simple integration into existing training pipelines and supports a wide range of model architectures and use-cases out of the box. It is available as a Python package or Docker container and runs fully on-premises.
Key value proposition:
- No Labels Required: Speed up development by pretraining models on your unlabeled image and video data.
- Domain Adaptation: Improve models by pretraining on your domain-specific data (e.g. video analytics, agriculture, automotive, healthcare, manufacturing, retail, and more).
- Model & Task Agnostic: Compatible with any architecture and task, including detection, classification, and segmentation.
- Industrial-Scale Support: LightlyTrain scales from thousands to millions of images. Supports on-prem, cloud, single, and multi-GPU setups.
Supported models and libraries:
- YOLOv5–v12, RT-DETR, ResNet, Vision Transformers, and more.
- Torchvision, Ultralytics, TIMM, SuperGradients, and more.
Benchmarks
LightlyTrain has been benchmarked across multiple regimes:
- Diverse model architectures
- Different dataset sizes
- Domain specific datasets
1. LightlyTrain Model Architecture Generalization
This benchmark highlights how LightlyTrain works with various models. For this purpose, the models were first pretrained with LightlyTrain on the full COCO dataset without labels. Then each model was fine-tuned with labels using only 10% of the COCO dataset to highlight typical industry use-cases where datasets are only partially labeled. All models pretrained with LightlyTrain show improved detection performance compared to their ImageNet or non-pretrained counterparts.
YOLO Series
YOLO is one of the most popular model series for object detection tasks. Pretraining with LightlyTrain yields up to 14% higher mAP compared to starting from ImageNet pretrained weights and up to 34% higher mAP compared to no pretraining. We observe consistent improvements for different YOLO versions (v8, v11, and v12) and model sizes (S and L).
.png)
RT-DETR
RT-DETR is a modern alternative to YOLO object detectors. For RT-DETR we achieve a performance increase of +1.2% mAP with pretraining compared to initializing the model with supervised ImageNet weights.
Faster R-CNN
Classic architectures like Faster R-CNN, which has a ResNet50 backbone with a detection head on top, also benefit from pretraining with LightlyTrain. In this case we observe up to 3.6% higher mAP compared to ImageNet weights. This showcases how LightlyTrain can be integrated into established training pipelines to further improve model performance.

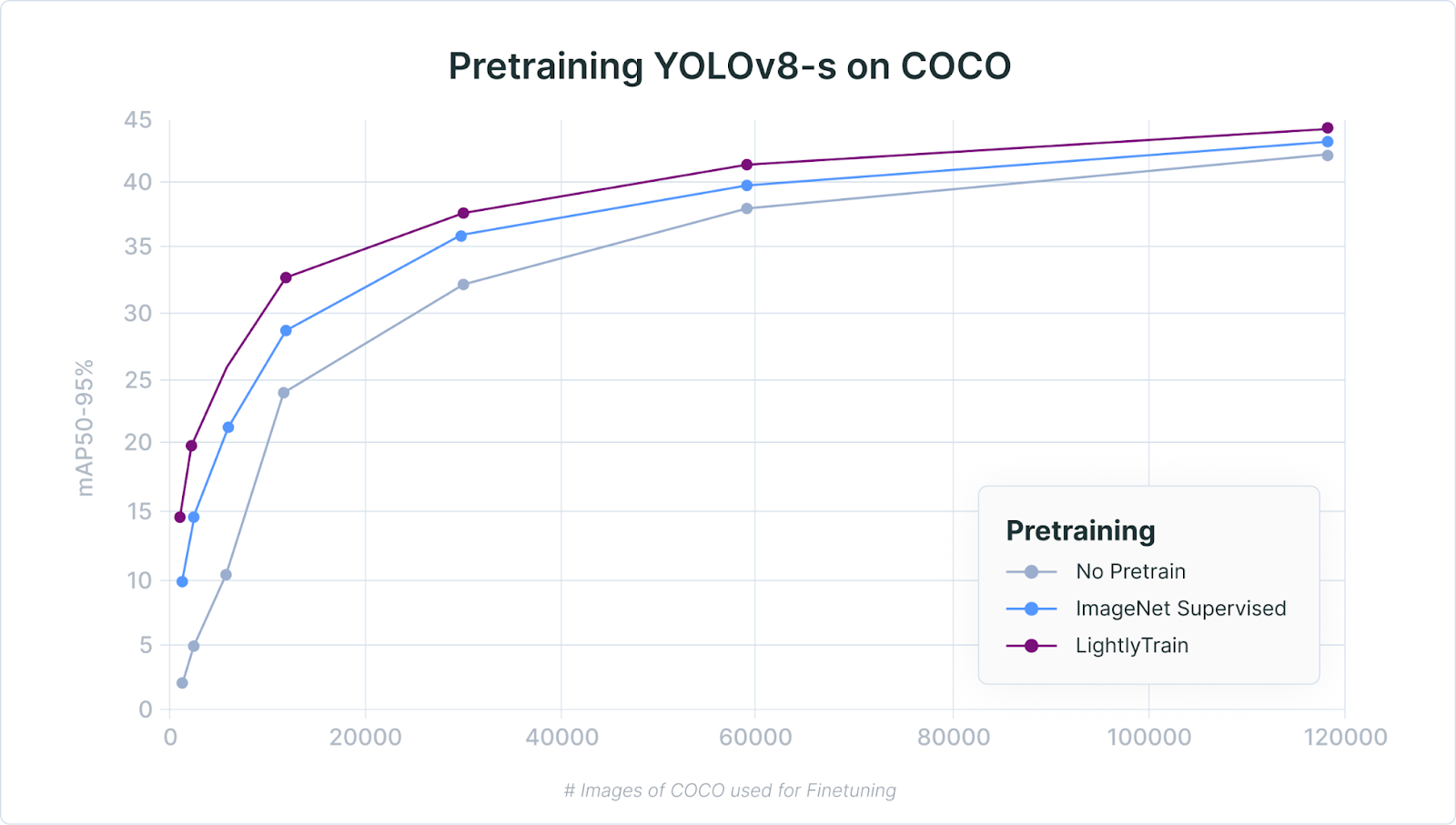
2. LightlyTrain Performance Across Dataset Sizes
The following plot highlights the benefits of pretraining across different dataset sizes. Especially in cases where only little labeled data is available (left of the plot) the benefit of starting from a pretrained model becomes even more evident. When fine-tuning on only 1’200 labeled images, LightlyTrain yields a +50% mAP gain over ImageNet weights.
This can be attributed to the pretraining which has access to a large number of unlabeled images from the COCO dataset. The pretrained model is therefore already well adapted to images from this dataset before the fine-tuning. The ImageNet model on the other hand is pretrained on other data and only sees the 1’200 COCO images during fine-tuning, making it much harder for the model to adapt to the new dataset.
Even with larger dataset sizes LightlyTrain pretraining continues to outperform the baseline by a large margin.
3. Domain-Specific Results
There are many pretrained models publicly available. However, most of them are trained on a few well-known datasets like ImageNet or COCO. While such models have demonstrated great performance on many tasks, they struggle to generalize to data that is significantly different from the data they were originally trained on. With LightlyTrain you can avoid this issue by pretraining models on the data from the same domain as your downstream task.
Automotive
BDD100K (Automotive - Detection, RT-DETR)
Pretraining on unlabeled video frames from BDD100K allows LightlyTrain to deliver the best performance when fine-tuning on labeled driving scenes.

Medical
DeepLesion (Medical - Detection, YOLO11x)
Under strong domain shifts like medical imaging, LightlyTrain also outperforms ImageNet pretraining. In this case we observe +1.1% mAP improvement on a lesion detection task from CT scan images.

Agriculture
DeepWeeds (Agriculture - Classification, ResNet50)
LightlyTrain helps models adapt more effectively to agricultural data, outperforming ImageNet pretraining by +4.3% top1 accuracy on a classification task.

How to Get Started with LightlyTrain
Getting started with LightlyTrain is easy.
Installation:
pip install lightly-train
Then start pretraining with:
import lightly_train
if __name__ == "__main__":
lightly_train.train(
out="out/my_experiment", # Output directory
data="my_data_dir", # Directory with images
model="torchvision/resnet50", # Model to train
)
Finally, load the pretrained model and fine-tune it using your existing training pipeline:
import torch
from torchvision import models
# Load the pretrained model
model = models.resnet50()
model.load_state_dict(torch.load("out/my_experiment/exported_models/exported_last.pt"))
# Fine-tune the model with your existing training pipeline
...
Resources:
- Documentation: https://docs.lightly.ai/train
- GitHub: https://github.com/lightly-ai/lightly-train
- Product Page: https://www.lightly.ai/lightlytrain
- Demo Video: https://youtu.be/5Lmry1k_cA8
LightlyTrain is available as a Python package and Docker container. All training runs can be executed fully on-premise — no internet access or telemetry required.
Licensing & Commercial Usage
LightlyTrain is available under AGPL-3.0 for open-source use. Commercial licenses are available — book a demo with our team to learn more.


Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.

-min.png)
-min.png)
-min.png)


