
Vector Indexes and Image Retrieval using LightlySSL
Recently, Vector Indexes have gained a lot of popularity with the rise of easy-to-use models, but most of these indexes are catered towards language models. In this article, we’ll provide an introduction to vector indexes using the faiss library, and provide code to pre-train a model using the various methods available in LightlySSL while following MLOps best practices with the use of Weights & Biases. In particular, we will use Weights & Biases to store our vector index generated using embeddings from our pre-trained model.
The Image Retrieval app that we’ll be building in this article for retrieving food images based on the Food101 dataset can be found at this Gradio Space.
What can I use them for ?
There are a lot of uses for Embeddings, particularly in Computer Vision. In this example, we’ll focus on Image Retrieval as an important use case.
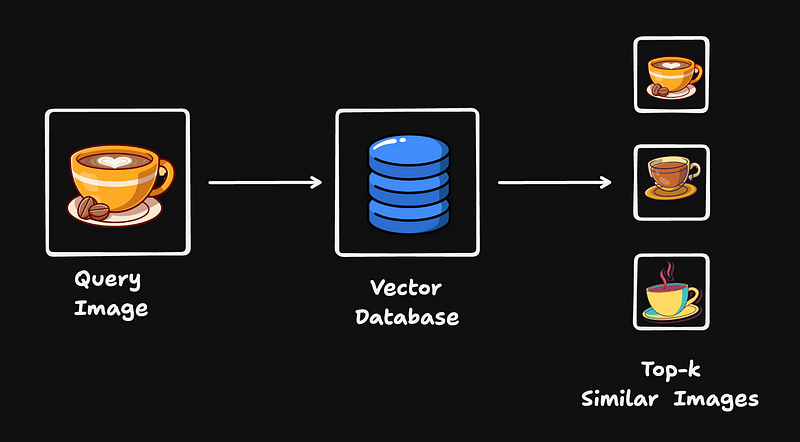
Image Retrieval is the task of looking for similar images given a query image from a given dataset of images. It is one of the most used methods in Computer Vision. Think about when you click an image on Google, it displays similar images, or when you want similar pins on Pinterest. These recommendation systems rely on image retrieval to get similar images. In this article, we’ll build an image retrieval system to return similar images from the food101 dataset.
What are Vector Indexes and why use them ?
Vector indexes are a form of data structure used for storing high-dimensional vectors. The key difference between vector indexes and simple hash maps is in the way that these vectors are stored together. Vectors are stored in a manner such that “similar” vectors are stored together in memory, thereby ensuring quick search.
Many types of indexes use different methods for storing vectors, but in this article, we are going to use the simplest version, viz. IndexFlatL2 which just performs brute-force L2 distance search. A list of all available indexes is documented in the faiss wiki.
But why should we use vector indexes? Can’t we just store our vectors in a dictionary and index using some smartly defined key? Vector indexes provide some significant advantages when compared to dictionaries, viz.
- Similarity Search: Since vector indexes store “similar” vectors together, getting the top 3 vectors for some query is as easy as specifying a parameter. On the other hand, using a dictionary would involve calculating the similarity from every other vector thereby increasing average query time.
- Efficient Serialisation: Serialising dictionaries is not an easy operation, depending on the data type of the key, while JSON is the widely used format, it does not scale to the needs of the industry.
Why Self-Supervised Learning methods ?

Supervised Learning is limited (and enabled) by labeled data. While there are labeled academic datasets available to researchers, they don’t reflect the needs of the industry. Moreover, supervised learning leads to task-specific representations. Real-life use-cases of computer vision involve dealing with data drift and lack of annotated labels. For most use-cases, it is a smarter choice to train a model using Self-Supervised learning rather than paying for expensive labelling services since they can leverage large unlabelled datasets.
Moreover, Self Supervised Learning is extremely useful in cases where we don’t know the task beforehand or want to train a model for multiple tasks. While multi-task learning has made great strides in recent years, it’s too computationally expensive and fragile for most companies to undertake. It’s in cases like this when Self Supervised Learning emerges as the best way to learn general-purpose rich representations for the underlying data.
How do I do it ?
Creating the dataset
In this example, we’ll be using the food101 dataset from the 🤗 huggingface hub. The methods described in this blog post are versatile enough to be used for any dataset from the huggingface ecosystem as long as the images are stored using the “image” key.
If your datasets is in a simple flat directory, LightlySSL can work with that as well. For more details please refer to our Structure your input tutorial.
Pre-train using Self Supervised Learning
Now that we have our dataset and dataloaders figured out, comes the choice of choosing a Self Supervised Learning method. There is a lot to choose from! We covered some of the recent trends in an article.
LightlySSL provides implementations of various methods with example integrations with popular frameworks viz. pure pytorch, Pytorch Lightning, and its distributed variants. As an example let’s look at DINO from Emerging Properties in Self-Supervised Vision Transformers. The following code snippet summarises the training loop of DINO while logging all our metrics to a weights and biases dashboard.
To see the full code for pretraining a model using DINO on the food101 dataset please refer to the associated Colab Notebook.
Create a Vector Index
Now let’s create a vector index using the faiss library, as mentioned before we’ll be creating a simple IndexFlatL2 index. The following code snippet summaries the necessary steps:
- Apply a standard set of transforms to the images such as resizing, normalization, and colorisation.
- Generate embeddings from the model using the augmented image
- Add the embeddings to the image, it’s in this step that the index places similar embeddings together.
Now this operation is comparatively expensive (~20 mins, with the index taking up ~600MB in memory), if we want to do image retrieval it makes sense to serialise the index and save it in cloud storage. Since we are using Weights & Biases as our MLOps dashboard, let’s save the index to the same workspace as an artifact.
Search/Query the Index
Now that we have our index stored in an artifact, when we create an application/server for Image Retrieval we can simply download and load the index using the following snippet.
This now establishes the lineage of artifacts in our project, viz.

Then, a given image embedding (possibly generated from the same model) can be used to query for the top k similar vectors. Since we use an insertion algorithm based on distance (L2), this ensures that the search procedure is quick.
This Colab Notebook contains the code to use a pretrained DINO model provided by LightlySSL to generate the embeddings, log the index to wandb, and then use the logged index to query an image from the food101 dataset.
Now we can pass an embedded image (query) and get the top 3 most similar images.
Now if the Image Retrieval system works well, for any given query from the dataset the first retrieved image should be the image itself. This indicates that the system can accurately match identical images and that the underlying representations are sufficiently discriminative.

References
- Vector Arithmetic with LanceDB: An intro to Vector Embeddings
- Image Similarity with HuggingFace Datasets and Transformers
- Emerging Properties in Self-Supervised Vision Transformers
- Image Retrieval with DINOv2
Conclusion
In this article, we saw how we can create an Image Retrieval System on an arbitrary dataset from the huggingface hub, pre-train a Self Supervised Learning model using LightlySSL, create a vector index using faiss, and then query for similar images all while using best practices using Weights & Biases.
Saurav,
Machine Learning Advocate Engineer
lightly.ai
.png)


.png)






.png)
-min.png)
-min.png)