
Computer Vision Hub
Explore cutting-edge computer vision guides, from foundationnal concepts to advanced implementations. Join thousands of developers and researchers advancing the field.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Computer Vision Hub

Advanced
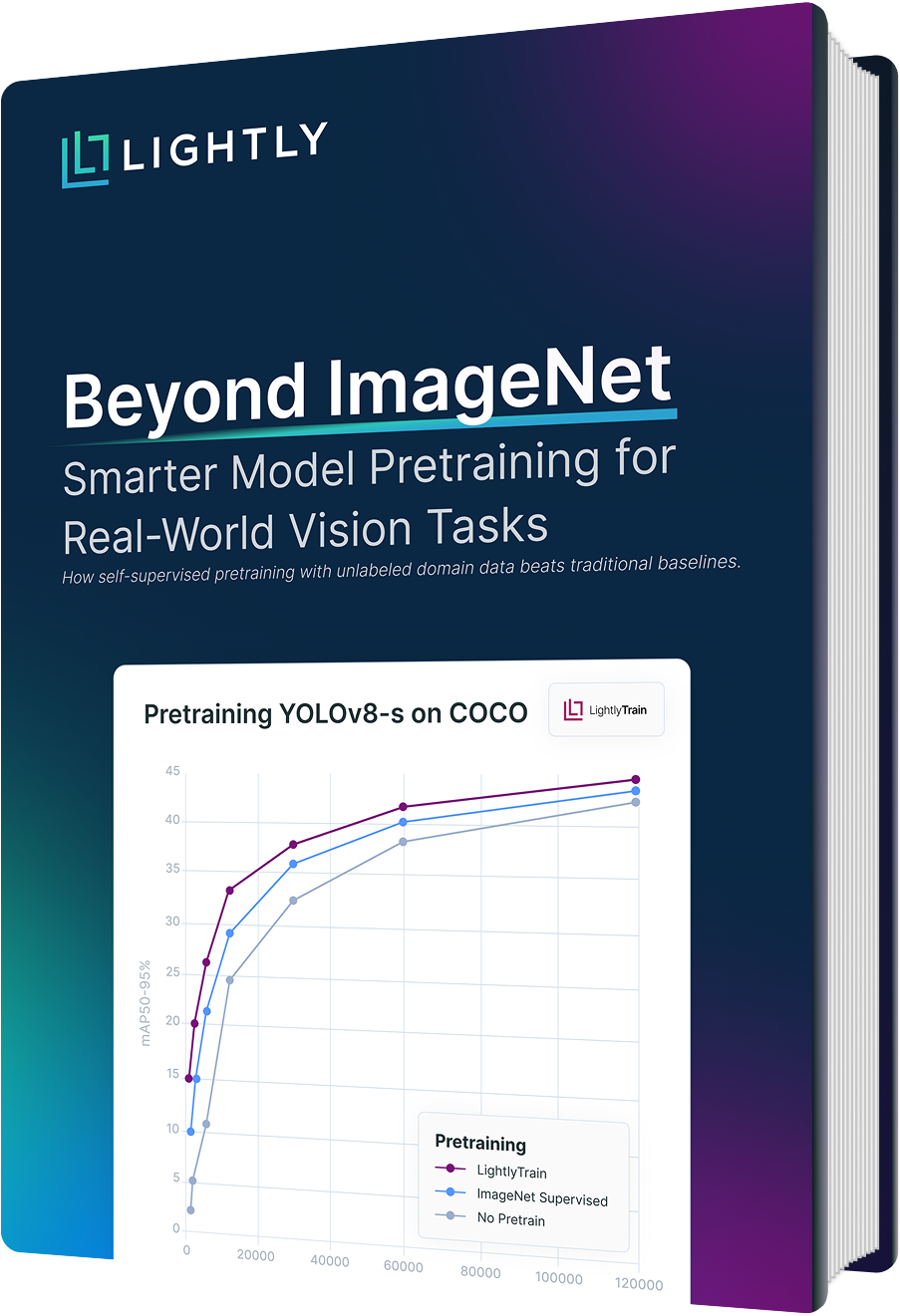
Beyond ImageNet: Smarter Model Pretraining for Real-World Vision Tasks
This guide shares benchmarks comparing domain-specific, self-supervised pretraining (e.g., with DINOv2) against ImageNet across popular models like YOLOv8, highlighting where traditional baselines fall short.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

Model training


.png)

Explore Lightly Products
.svg)

LightlyTrain
Self-Supervised Pretraining
Leverage self-supervised learning to pretrain models
Learn More

LightlyServices
AI Training Data for LLMs & CV
Expert training data services for LLMs, AI Agents and vision
Learn More


