
The 101 Introduction to Multimodal Deep Learning
Table of contents
Share blog post



Discover how multimodal models combine vision, language, and audio to unlock more powerful AI systems. This guide covers core concepts, real-world applications, and where the field is headed.
Share blog post
Below you can find a quick summary of the key points about multimodal deep learning.
- What is multimodal deep learning?
Multimodal deep learning is a subfield of machine learning where deep neural networks learn from multiple modalities of data (e.g., images, text, audio) simultaneously, instead of just one. This allows a model to process visual data alongside natural language, audio, etc., for a more holistic understanding.
- How does multimodal deep learning work?
Multimodal models use separate neural network components (like an image encoder for visual input and a language model for text) to extract features, then fuse these representations (often via an attention mechanism or joint layers) into one combined understanding. Essentially, the model aligns and merges information from different modalities to make predictions.
- What are the applications of multimodal deep learning?
Such models unlock tasks like Visual Question Answering (VQA) (answering questions about images), image captioning (generating descriptions for images), text-to-image generation (creating images from text prompts), image retrieval with text queries, emotion recognition from video+audio, and many others that single-modality models can’t perform as effectively.
- Why is multimodal deep learning important and gaining traction?
By leveraging information from multiple sources (like combining vision and language), multimodal deep learning systems achieve higher accuracy and more human-like understanding than unimodal systems. Recent breakthroughs in large language models (LLMs) and vision models have spurred interest in merging them, leading to large multimodal models with impressive capabilities. In short, combining modalities enables deep learning models to generalize better to complex, real-world scenarios that involve multiple input modalities.
Recent AI breakthroughs, like OpenAI’s GPT-4 Vision and Google’s Gemini 2.0, signal a shift toward multimodal deep learning—merging text, images, audio, and more into unified, context-rich systems.
GPT-4 Vision blends text and visual data for tasks like scene interpretation, while Gemini handles broader streams, including video and audio, showcasing multimodal versatility. By combining these data types, AI gains nuanced, human-like understanding, far surpassing unimodal limits.
This article will explore multimodal learning, why it’s important, how it works under the hood (from encoders to feature fusion), key training considerations, challenges to overcome, and real-world applications. We will also point to popular datasets and resources for diving deeper into multimodal learning.
To understand its scope, we first define the basics of multimodal learning.
What is Multimodal Learning in Deep Learning?
In multimodal deep learning, a model is trained on data that includes multiple modalities – different forms of information such as text, images, audio, and video.
Instead of learning from one input type alone, the model integrates information from various sources. The goal is to leverage the complementary strengths of each modality to make more accurate and comprehensive predictions.
For example, a multimodal system might analyze an image with a descriptive caption rather than treating it alone. By processing these together, the model can capture correlations (like matching spoken words to objects in a video) that would be invisible to a single-modality model.
Why is Multimodal Learning Important?
The importance of multimodal learning lies in its ability to address complex, real-world problems that are inherently multimodal. Many tasks require integrating information from various data types. For example:
- Visual Question Answering (VQA): Answering questions about images that requires both visual understanding and language comprehension.
- Image Captioning: Generating textual descriptions of images, combining vision and language.
- Emotion Recognition: Detecting emotions from video and audio, integrating visual cues (facial expressions) with auditory cues (tone of voice).
- Autonomous Driving: Processing data from cameras, LiDAR, and other sensors to navigate safely, which involves multiple modalities.
By leveraging multimodal data, these models can achieve higher accuracy and more robust performance than unimodal models, as they can capture complementary information that might be missing in a single modality.
Data Modalities in Multimodal Deep Learning
Multimodal learning relies on integrating distinct data modalities, commonly including:
- Text: Provides semantic information, capturing meaning and intent.
- Vision: Images and video offer spatial and visual context.
- Audio: Captures nuances in speech, sounds, and emotional tone.
Additionally, specialized modalities include:
- LiDAR offers precise depth and spatial data, critical in autonomous driving.
- Medical Imaging: Enhances diagnostic accuracy when combined with clinical records.
- Physiological Sensors: EEG and ECG data for comprehensive medical assessments.
Each modality brings unique strengths, contributing vital context. Images and video enrich spatial understanding; text provides semantic clarity, and audio complements emotional and situational nuances. Effectively merging these strengths allows multimodal models to achieve richer, more accurate representations, facilitating powerful and nuanced decision-making across applications.
A relevant video resource for understanding these modalities is available on YouTube Video, which explains multimodal data processing.
💡 Pro Tip: Master embeddings for multimodal fusion. See why they matter in the Importance of Embeddings guide.
How Multimodal Learning Works in Deep Learning
Multimodal learning involves several key steps, each critical for processing and integrating diverse data types:
Modality-Specific Encoders
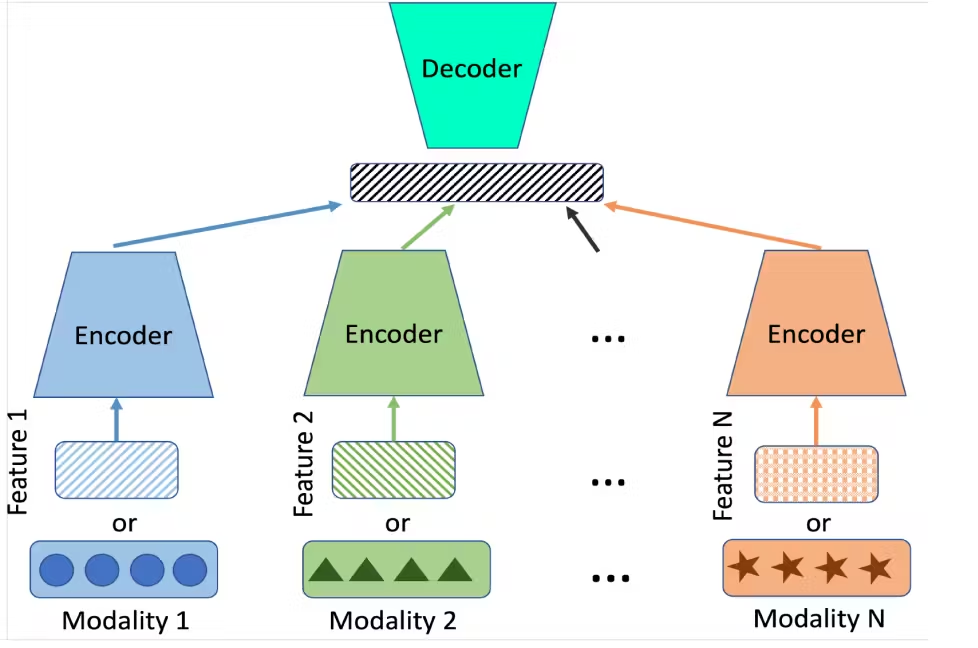
Multimodal models process each input modality with a dedicated encoder tailored to that data type. For instance, an image encoder might use a CNN like ResNet, while a text encoder could use a Transformer model like BERT.
These encoders extract features specific to each modality, ensuring that the unique characteristics of images, text, or audio are captured effectively. For example, ResNet might output a 2048-dimensional feature vector for an image, while BERT might produce a 768-dimensional embedding for a sentence.
The output of each encoder is a feature vector or set of features capturing the information in that modality. For example, an image encoder might output a 128-dimensional vector representing the image’s content, while a text encoder produces a similar vector for the semantic meaning of the text.
These embeddings are often projected into a shared latent space to facilitate fusion, ensuring that different modalities can be compared or combined. This alignment is crucial for tasks like cross-modal retrieval, where the model needs to match images with text descriptions.
Fusion Techniques
A multimodal model must fuse information from the different modalities after obtaining embeddings. There are several strategies:
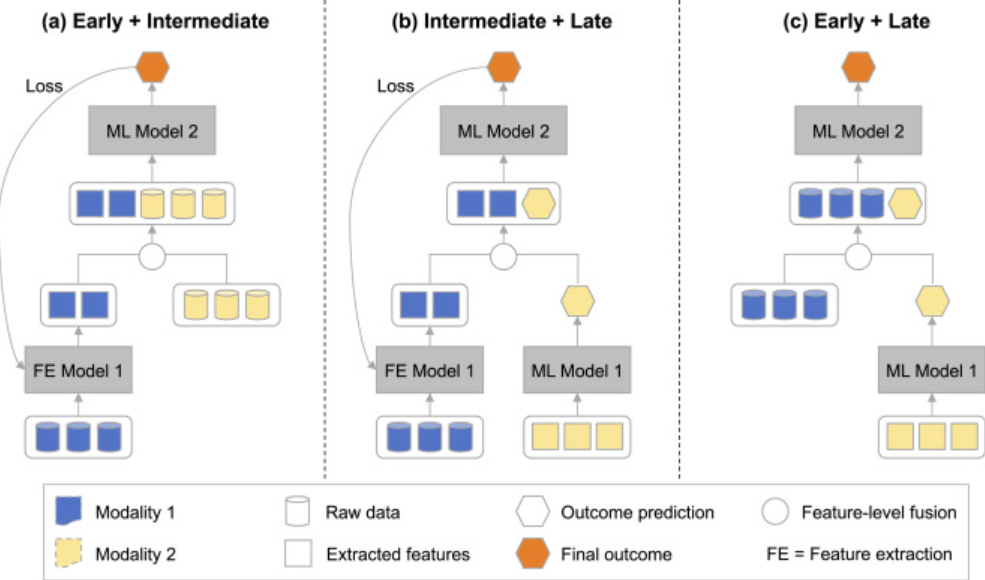
Early Fusion (Feature-Level Fusion)
Concatenate or combine the raw features or embeddings from each modality early in the model, then process them together. For example, an image feature vector and a text embedding vector can be concatenated into one long vector, which is then fed into subsequent layers jointly.
Early fusion preserves information from all modalities, allowing the network to learn cross-modal interactions immediately. It is essentially vector concatenation and ensures no modality is omitted initially. However, it may require careful preprocessing (to normalize scales of features) and may lead to very high-dimensional inputs, increasing computational costs.
Code Example
To illustrate, consider a simplified PyTorch model for a vision-language task, where an image is encoded with a CNN (ResNet) and text with a Transformer, then fused via early fusion for classification. This example, while basic, demonstrates how modalities are processed and combined, highlighting the practical implementation of these concepts:
import torch
import torch.nn as nn
import torchvision.models as models
from transformers import BertModel
class VisionLanguageEarlyFusion(nn.Module):
"""
Simple vision-language model using early fusion
- Image features from ResNet18
- Text features from BERT
- Early fusion by concatenation
"""
def __init__(self, num_classes=10):
super().__init__()
# Image encoder (ResNet18) - outputs 512-dim features
self.image_encoder = models.resnet18(pretrained=True)
self.image_encoder = nn.Sequential(*list(self.image_encoder.children())[:-1])
# Text encoder (BERT) - outputs 768-dim features
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
# Early fusion and classification
self.classifier = nn.Sequential(
nn.Linear(512 + 768, 256), # Concatenated features
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, num_classes)
)
def forward(self, images, input_ids, attention_mask):
# Process images
batch_size = images.size(0)
image_features = self.image_encoder(images)
image_features = image_features.view(batch_size, -1) # Flatten: [B, 512]
# Process text
text_outputs = self.text_encoder(input_ids=input_ids, attention_mask=attention_mask)
text_features = text_outputs.last_hidden_state[:, 0, :] # [CLS] token: [B, 768]
# Early fusion: concatenate features
fused_features = torch.cat([image_features, text_features], dim=1) # [B, 1280]
# Classification
output = self.classifier(fused_features)
return output
# Example usage
def main():
# Model initialization
model = VisionLanguageEarlyFusion(num_classes=10)
# Dummy inputs (for demonstration)
batch_size = 4
images = torch.randn(batch_size, 3, 224, 224) # [B, C, H, W]
input_ids = torch.randint(0, 30522, (batch_size, 128)) # [B, seq_len]
attention_mask = torch.ones(batch_size, 128) # [B, seq_len]
# Forward pass
with torch.no_grad():
outputs = model(images, input_ids, attention_mask)
print(f"Output shape: {outputs.shape}") # [B, num_classes]
if __name__ == "__main__":
main()The code demonstrates:
- Image encoding using ResNet18 to extract visual features (512 dimensions)
- Text encoding using BERT to extract textual features (768 dimensions)
- Early fusion by concatenating these features (1280 dimensions total)
- A simple classifier that processes the fused features
For a more advanced model, hybrid fusion (discussed below) with cross-modal attention could be implemented, allowing the text encoder to attend to image features and enhancing cross-modal understanding.
Late Fusion (Decision-Level Fusion)
The late fusion technique processes each modality independently through its encoder and possibly modality-specific layers and only combines the outputs at the end. Each modality might produce a prediction (or a high-level feature) in a late fusion setup. Then, these predictions or features are combined (e.g., averaged, weighted, or through a small neural network) to produce the final output.
Late fusion allows each modality to be modeled in-depth, leveraging the strengths of each modality’s network without interference. It is also interpretable since one can inspect each modality’s output before fusion. The downside is that the model might learn to rely on the most predictive modality and ignore others until the final step. It doesn’t learn joint feature representations early on, potentially missing cross-modal relationships.
Hybrid Fusion (Mid-Level or Joint Fusion)
A combination of early and late fusion that merges modalities at intermediate layers and may allow multiple interaction points. One popular approach is using cross-modal attention: it allows the model to determine "which parts of modality A should I pay attention to, based on what I know from modality B?"
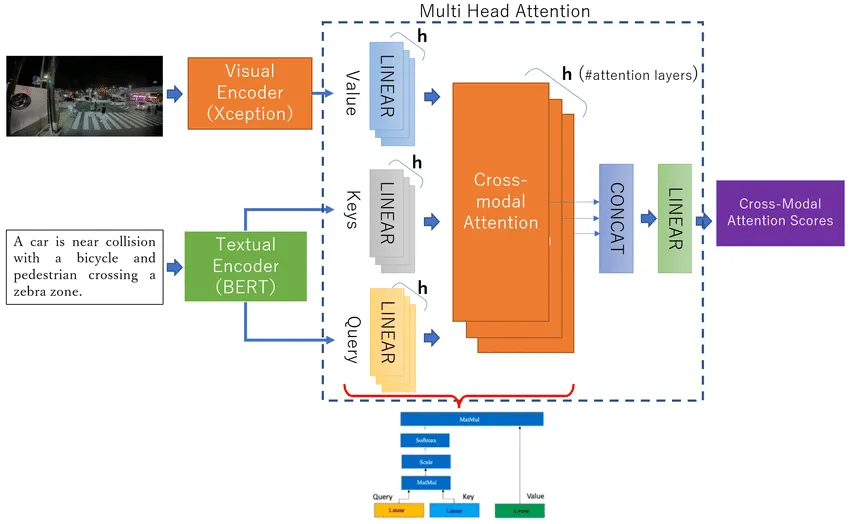
In this figure, cross-modal attention works by connecting visual and textual information through a query-key-value mechanism. The system calculates attention scores that represent the strength of connections between specific textual concepts (like "car" or "collision") and visual elements in the scene. After processing through multiple attention heads and linear transformations, the model produces cross-modal attention scores that reveal how strongly each textual element relates to different visual features.
Another hybrid approach is to project all modalities into a shared latent space (as in joint embedding models like CLIP) during training, effectively fusing by aligning representations rather than by direct concatenation.
Hybrid fusion aims to capture complex relationships but tends to make the model architecture more complex, requiring more computational resources and careful design.
Multimodal Model Training Considerations
Training multimodal models involves several considerations to ensure effective learning:
Loss Functions
Multimodal deep learning trains AI models on different data types, like images and text, using specific loss functions to measure errors and improve performance.
Cross-entropy loss is common for classification tasks, while contrastive losses are used for tasks like aligning image and text embeddings (e.g., in CLIP). Other losses, such as triplet loss for similarity learning, may be employed for multimodal retrieval tasks.
Contrastive losses, in particular, are crucial for tasks requiring alignment, such as ensuring that an image of a cat and the text "a cat" are mapped close together in the embedding space.
Data Alignment
Ensuring that data from different modalities is synchronized is crucial. For example, in video captioning, the timing of video frames must align with the corresponding text or audio. Misalignment can occur due to differences in sampling rates, sequence lengths, or inherent characteristics of the modalities (e.g., temporal differences between video frames and audio).
Data alignment ensures that different modalities are synchronized and their relationships are established, enabling effective fusion for downstream tasks. The table below summarizes the common data alignment techniques and their applications in multimodal deep learning.
Handling Imbalance
Modality imbalance, where one modality dominates in quantity or informativeness, can bias the model. Techniques like weighted sampling, modality dropout (randomly omitting a modality during training), or curriculum learning can help mitigate this issue, ensuring the model learns from all modalities effectively.
💡 Pro Tip: Are you struggling with training efficiency? Check out Knowledge Distillation Trends for techniques to streamline multimodal model training.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Multimodal Learning Challenges
Multimodal deep learning, blending different data modalities, faces significant deployment challenges. Some key challenges include data alignment, modality imbalance, computational costs, and missing modalities.
Data Alignment Issues
As discussed before, syncing different data modalities—like video clips and their audio and text —is hard because they don’t always match up naturally. If they’re off, the model can get confused, mixing up unrelated stuff and hurting accuracy, like captions missing the mark in a video.
Modality Imbalance and Bias
Imbalance happens when one modality—like text—has more data or stronger predictive value than others, such as images or audio. This causes bias, where the model over-relies on the dominant modality during training, effectively sidelining the rest.
For example, if audio carries 90% of the signal in a video dataset, the model might ignore visual features, acting like an unimodal system. This skew, called unimodal bias, degrades performance if the dominant modality is missing during inference, as the model hasn’t learned to leverage the others effectively.
Computational Costs
Multimodal models can be computationally heavy. Processing multiple input streams (especially long sequences or high-res images) and performing cross-modal attention multiplies memory and compute costs. For instance, joint processing of a 2048-token paragraph and a 2048-token image (patch sequence) would require attention over 4096 tokens, which is quadratic in complexity.
💡Pro Tip: If you plan to add geometric information to multimodal representation learning, our Monocular Depth Estimation article explains how depth predictions can enhance scene understanding.
Missing Modalities
In real-world deployment, it’s common for one or more modalities to be missing or unavailable. Sensors fail, or a particular input (like a descriptive caption) might not be provided at runtime.
Multimodal models must be robust to these situations. Late fusion architectures have an advantage here – if one tower’s input is missing, the other can still produce an output. For early-fusion models, one often has to supply a default token or a mask to represent the missing data and hope the model learns to handle it.
Applications of Multimodal Learning
Multimodal learning enables a wide range of applications, each leveraging the integration of different data types.
- Image Captioning: Generates textual descriptions from visual input. Example: An image processing pipeline identifies a "gray cat sitting on a blue couch" by extracting visual features and mapping them to language constructs.
- Visual Question Answering (VQA): Processes natural language queries about visual content. Implementation typically involves convolutional neural networks for image feature extraction and transformers for question comprehension.
- Emotion Recognition: Integrates multiple modalities (facial expressions, vocal acoustics, linguistic content) to classify emotional states. Example: To identify sarcasm, a trimodal system might detect incongruence between positive verbal content and negative vocal tone.

- Image Retrieval: Enables semantic search across modalities using embedding alignment techniques. Query: "sunset over the ocean" → Retrieved images ranked by semantic similarity in joint embedding space.
- Text-to-Image Generation: Converts textual descriptions to visual representations using generative adversarial networks or diffusion models. Example: Prompt "futuristic city at night" generates corresponding synthetic imagery.

- Speech-to-Text Generation: Transcribes acoustic signals to text, enhanced by visual cues for disambiguation. Example: Audiovisual models achieve higher accuracy by incorporating lip movements for phonetically similar sounds.
- Text-to-Sound Generation: Synthesizes acoustic output from textual descriptions using spectrogram prediction techniques. Example: Text prompt "thunderstorm" generates appropriate audio waveforms with rainfall, wind, and thunder components.
These applications demonstrate the versatility of multimodal learning, enabling tasks that require understanding across different data types, often outperforming unimodal approaches.
💡 Pro Tip: Boost your image-text tasks with models like CLIP. Dive into their mechanics with CLIP and Friends.
Popular Multimodal Datasets
Multimodal datasets are essential for training and evaluating models. Below is a table summarizing the key datasets mentioned, with short descriptions and links where available:
💡 Pro Tip: Need tools to manage large datasets? Discover top picks in Best Computer Vision Tools to streamline your workflow.
Multimodal Deep Learning: Key Takeaways and Further Reading
Multimodal deep learning fuses diverse data modalities—text, images, audio— using robust AI techniques. This section distills key insights from its mechanisms, challenges, and applications alongside curated resources for deeper technical exploration.
Key Takeaways
- Multimodal deep learning integrates text, images, audio, etc., for richer, context-aware AI predictions.
- It combines data with modality-specific encoders (e.g., CNNs, Transformers) and fusion techniques (early, late, hybrid).
- Data alignment, modality imbalance, high computational costs, and missing modalities are key challenges.
- It outperforms unimodal models by leveraging complementary data strengths, mimicking human perception.
- Applications like image captioning, VQA, emotion recognition, and autonomous driving showcase its versatility.
- Solutions like dynamic time warping, weighted sampling, and modality dropout address deployment hurdles.
Further Reading
Below is a curated, categorized list of resources for deeper exploration of multimodal deep learning, presented with concise technical descriptions:
Survey Papers
- Multimodal Alignment and Fusion: A Survey: Provides an in-depth review of alignment methods (e.g., dynamic time warping, attention) and fusion techniques, foundational for understanding multimodal system design. (Link)
- A Comprehensive Survey on Deep Multimodal Learning with Missing Modality: Analyzes challenges like missing data and modality imbalance, offering practical insights into robust model development. (Link)
Open-Source Repositories
- OpenFlamingo: A framework for constructing vision-language models, including pre-trained weights, optimized for rapid prototyping and experimentation. (Link)
- LAVIS: A toolkit with pre-trained multimodal models and utilities, supporting tasks like image captioning and visual QA with high efficiency.
Lightly in Action: Accelerating Your Large Vision Model Development
Building and deploying Large Vision Models (LVMs) requires extensive, high-quality image datasets, efficient training strategies, and optimized inference workflows. Lightly simplifies this process, accelerating your computer vision projects' pre-training and adaptation phases.
Here’s how Lightly can enhance your large vision model workflows:
LightlyTrain: Streamline your pre-training workflows using advanced embedding and clustering techniques. By automatically curating representative subsets of your visual data, LightlyTrain ensures your models learn more efficiently and robustly, reducing the amount of labeled data needed and accelerating time-to-deployment for domain-specific large vision models.
💡 Pro tip: Optimize your multimodal vision model training with curated datasets. Learn advanced techniques in our guide on Efficient VLM Training.
LightlyOne: Improve the quality of your datasets and significantly reduce labeling costs with intelligent data selection. LightlyOne automatically identifies and filters redundant or low-quality images, optimizing your datasets for superior model accuracy and performance in downstream tasks like object detection, segmentation, and zero-shot or few-shot learning.
💡 Pro tip: New to vision-language models? Get a solid foundation with our Introduction to Vision-Language Models to see how LightlyOne fits in.
LightlyEdge: Optimize the deployment of large vision models directly at the edge with powerful on-device inference and intelligent data filtering. LightlyEdge allows your computer vision applications to run faster and more efficiently, minimizing latency and bandwidth, crucial for real-time industrial applications, autonomous driving, and other edge scenarios.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


