Large Vision Models (LVMs) are reshaping the field of computer vision. With the ability to process and understand complex visual data, these models are powering everything from image generation to content moderation.
In this article, we’ll explore how LVMs work, compare leading models like CLIP, DINOv2, and SAM, and look at how they’re being applied across industries. We’ll cover the following:
What are Large Vision Models
Comparison of LVMs
Architecture of LVMs
Key Features & Training Strategies for Large Vision Models
Fine-tuning and Adaptation of LVMs
Real-world Applications of LVMs
Limitations and Challenges
Future Trends & Research
Now, let’s dive in.
What are LVMs?
Large Vision Models (LVMs) are deep neural networks designed for image processing and computer vision tasks like recognition, segmentation, text-to-image generation, and multimodal reasoning.
Much like large language models, LVMs are trained on massive image datasets—often accompanied by textual descriptions—allowing them to understand intricate visual patterns and perform a variety of vision-related tasks, such as image creation, visual search, wildlife tracking, and identity verification.
These models typically comprise millions to billions of parameters, enabling them to grasp complex features from visual data.
Comparison of most popular LVMs
With many CV models emerging across modalities, it’s important to evaluate their architecture, training strategies, and visual input and textual information processing capabilities. The following table highlights key differences between several leading LVMs to guide model selection for specific applications.
Table 1: Comparison of most popular LVM (By Author).
Model
Training Objective
Description
Main Advantage
Main Disadvantages
VIT
The objective of ViT's pretraining is to predict the image class using the representation of the [CLS] token after passing through the Transformer encoder.
The ViT is pretrained on image classification task, using the CLS token for image classification. Then, the same CLS token is used for fine-tuning tasks.
Because of Attention mechanism model learns global image features. Its ancestors (i.e. ResNet), which use Convolutional Neural Networks. The latest first part layers learn local patterns while last layers learn general
information about pictures. Attention beats CNN constantly keeping information about global features.
ViT requires large-scale datasets for training and is computationally expensive due to its self-attention, making it inefficient for smaller datasets without large-scale pretraining.
CLIP
The objective of CLIP's pretraining is to learn visual and textual representations by aligning images and their corresponding text descriptions in a shared embedding space.
CLIP uses image and text encoders to get embeddings and match those embeddings in embedding space using contrastive loss and negative sampled examples.
CLIP's primary advantage is its ability to align visual and textual data effectively within a shared embedding space, enabling zero-shot image classification and strong generalization to new, unseen concepts without additional labeled training data.
CLIP struggles with long-context text because it was trained primarily on short text-image pairs, making it less effective at extracting nuanced or contextualized meaning from longer textual inputs.
SAM
The objective of SAM's pretraining is to generate precise segmentation masks for any object in an image by learning from a large dataset of annotated images.
SAM (Segment Anything Model) is pretrained on image segmentation tasks, learning to generate precise masks for any object in an image. Then, the same model is used for fine-tuning on specific segmentation tasks to improve its accuracy in segmenting different objects across various domains.
SAM's strength lies in generating highly accurate segmentation masks universally applicable across diverse objects and domains, achieved through extensive training on a broad annotated image dataset, simplifying downstream fine-tuning and enabling rapid adaptation to specific tasks.
SAM requires significant computational resources and struggles with segmenting overlapping or occluded objects, sometimes producing incorrect masks in complex scenes.
DINOv2
The objective of DINOv2's pretraining is to learn self-supervised visual representations by maximizing the similarity between augmented views of the same image while maintaining uniqueness across different images.
DINOv2 is pretrained using a self-supervised learning approach, maximizing the similarity between augmented views of the same image while maintaining uniqueness across different images. Then, the learned visual representations are used for fine-tuning tasks like image classification, object detection, and other vision tasks.
Because of DINOv2's self-supervised objective, it captures robust and detailed information about images and provides great base for downstream tasks like object detection and semantic segmentation.
DINOv2 is highly dependent on the quality of its augmentations and lacks explicit supervision, which can lead to challenges in learning fine-grained details for certain tasks.
Stable Diffusion
The objective of Stable Diffusion's pretraining is to generate high-quality images from text prompts by learning the mapping between textual descriptions and image features using a diffusion-based generative model.
Stable diffusion takes image embeddings in latent space with some encoder model (VAE), adds gaussian noise with some policy and try to denoise it with defined time-stamps. As a result we get Denoising DIffusion Probabilistic Model, and we can give it a pure noise and based on our text description it generates an image.
The latent image distortion/distillation provides an opportunity to generate highly detailed and high-resolution images. The model's predictive power concentrates not on denoising each pixel but on denoising the image embedding, which has significantly lower dimensionality.
Stable Diffusion requires careful prompt engineering to achieve desired results, and its generation process is computationally intensive. It also struggles with compositional consistency across multiple generated images. It requires too much techniques to control generation process (Dreambooth, LoRA, ControlNet).
Flamingo
The objective of Flamingo's pretraining is to learn multimodal representations by jointly processing and understanding both text and images for tasks like visual question answering and captioning.
Flamingo is pretrained using a multimodal approach, learning to process both image and text inputs and align their representations in a shared space. Then, the model is fine-tuned on specific vision-and-language tasks like visual question answering, image captioning, and other multimodal reasoning tasks.
Flamingo excels in multimodal learning, effectively processing and aligning visual and textual inputs, thus greatly enhancing performance on vision-and-language tasks such as visual question answering, image captioning, and multimodal reasoning.
Flamingo's closed-source nature limits research accessibility, and it requires large-scale data and computational power, making it less practical for smaller organizations or researchers.
Sora
The objective of OpenAI's Sora is to enable large-scale vision and language models by learning to align and generate multimodal representations for a variety of tasks, such as vision-guided text generation, object understanding, and multimodal reasoning, using both images and text in an integrated manner.
Sora is pretrained using multimodal learning, aligning text and visual representations for tasks like image captioning and visual reasoning. Then, the model is fine-tuned on specialized tasks to improve performance in vision-language tasks across different domains.
Sora’s key advantage is its integration of multimodal learning, effectively aligning text and visual data. This alignment enhances performance in tasks requiring complex vision-language reasoning, such as image captioning, visual understanding, and reasoning.
Sora is not open-source, restricting experimentation and customization. Its reliance on multimodal data may also introduce biases and inconsistencies across different domains.
Gemini Pro Vision
The objective of Gemini Pro Vision is to enhance visual understanding and productivity by leveraging AI to analyze, interpret, and generate insights from images and videos, often applied in tasks like image classification, object detection, and automated visual reasoning.
Gemini Pro Vision is pretrained on a variety of image analysis tasks, learning to understand and interpret visual data in conjunction with other modalities. Then, it is fine-tuned for image classification, object detection, and automated reasoning in real-world scenarios.
Gemini Pro excels at interpreting and analyzing complex visual data, providing robust performance in real-world scenarios by integrating multimodal learning. It effectively enhances automated reasoning, image classification, and object detection tasks across diverse contexts.
Gemini Pro is proprietary and lacks public access, limiting its adaptability and customization. Additionally, it requires significant computational resources, making it less accessible for low-budget applications.
LLAVA
The objective of LLAVA model is to learn weights "translation" neural network layers, which take image embeddings embedded with the help of ViT and match to the embedding space of LLM that they chose for model training. They create synthetic dataset consisting from images and their corresponding explanations (for one
image we have several textual contexts).
LLAVA is pretrained by extracting image embeddings from ViT and aligning them with the latent space
of a language model. This alignment enables the model to process and understand visual information in a
textual context. The model uses a synthetic dataset, where each image is associated with multiple contextual explanations to enhance its visual-textual comprehension.
LLAVA's main advantage is its training dataset. It is constructed in a way that each image contains extensive textual descriptions, starting from item bounding box information and ending with detailed textual
explanations. This enables enormous reasoning capability and enhanced image understanding for the LLM.
LLAVA's main disadvantage is that its performance heavily depends on synthetic training data. The dataset needs to be diverse and highly descriptive, requiring deep prompt engineering for image descriptions. If it lacks diversity, the model may struggle with real-world scenarios.
Improve your data
Today is the day to get the most out of your data. Share our mission with the world — unleash your data's true potential.
Large Vision Models (LVMs) are transforming computer vision by using Transformer-based architectures to analyze images like language. From ViT to CLIP and GPT-4V, these models power advanced tasks like image recognition, generation, and multimodal understanding. Explore how they work and what makes them the future of visual AI.
Ideal For:
ML/CV Engineers
Reading time:
9 mins
Category:
Models
Share blog post
Quick summary of key points about AI model training techniques and their implementation.
TL;DR
What are Large Vision Models (LVMs)?
Large Vision Models are advanced deep learning models for computer vision with millions or billions of parameters, trained on vast image datasets to recognize complex patterns. They are the visual counterparts to large language models, often using Transformer architectures to achieve state-of-the-art results in tasks like image recognition and object detection.
How do large vision models work?
Most LVMs use Transformer-based architectures (originally from NLP) instead of traditional CNNs For example, a Vision Transformer (ViT) breaks an image into patches and processes them like tokens in a sequence. Others combine vision and language: models like CLIP have an image encoder and text encoder trained together to align images with captions. These models are first pretrained on huge datasets (e.g. ImageNet or web images) and then fine-tuned or prompted for specific tasks.
What are some examples of large vision models?
Vision Transformer (ViT) – Developed by Google, this was the first pure Transformer model for image classification.
CLIP – OpenAI’s contrastive vision-language model that aligns images with text representations.
Stable Diffusion – A popular text-to-image generative model enabling high-quality image synthesis.
Flamingo – DeepMind’s few-shot visual language model, designed to perform well with limited examples.
Sora – OpenAI’s text-to-video model capable of generating videos up to one minute long.
Gemini Pro Vision – Google’s multimodal model that processes text, images, and video inputs.
Midjourney – A widely-used generative image model known for its stylized artistic outputs.
GPT-4V (Vision) – An extension of OpenAI’s GPT-4 that can understand and analyze both text and images.
FLUX – A model series by BlackForestLabs (creators of Stable Diffusion). Learn more.
PaliGemma – An open-source model series from Google focused on vision-language tasks.
DINOv2 – Meta’s self-supervised learning model. Alongside CLIP, it’s one of the most impactful LVMs to date.
AIMv2 – Apple’s autoregressive visual language model. One of the first large-scale successful models in this class. This type of architecture is likely to shape the future of vision-language models, and should be especially highlighted.
Large Vision Models (LVMs) are reshaping the field of computer vision. With the ability to process and understand complex visual data, these models are powering everything from image generation to content moderation.
In this article, we’ll explore how LVMs work, compare leading models like CLIP, DINOv2, and SAM, and look at how they’re being applied across industries. We’ll cover the following:
What are Large Vision Models
Comparison of LVMs
Architecture of LVMs
Key Features & Training Strategies for Large Vision Models
Fine-tuning and Adaptation of LVMs
Real-world Applications of LVMs
Limitations and Challenges
Future Trends & Research
Now, let’s dive in.
What are LVMs?
Large Vision Models (LVMs) are deep neural networks designed for image processing and computer vision tasks like recognition, segmentation, text-to-image generation, and multimodal reasoning.
Much like large language models, LVMs are trained on massive image datasets—often accompanied by textual descriptions—allowing them to understand intricate visual patterns and perform a variety of vision-related tasks, such as image creation, visual search, wildlife tracking, and identity verification.
These models typically comprise millions to billions of parameters, enabling them to grasp complex features from visual data.
Comparison of most popular LVMs
With many CV models emerging across modalities, it’s important to evaluate their architecture, training strategies, and visual input and textual information processing capabilities. The following table highlights key differences between several leading LVMs to guide model selection for specific applications.
Table 1: Comparison of most popular LVM (By Author).
Model
Training Objective
Description
Main Advantage
Main Disadvantages
VIT
The objective of ViT's pretraining is to predict the image class using the representation of the [CLS] token after passing through the Transformer encoder.
The ViT is pretrained on image classification task, using the CLS token for image classification. Then, the same CLS token is used for fine-tuning tasks.
Because of Attention mechanism model learns global image features. Its ancestors (i.e. ResNet), which use Convolutional Neural Networks. The latest first part layers learn local patterns while last layers learn general
information about pictures. Attention beats CNN constantly keeping information about global features.
ViT requires large-scale datasets for training and is computationally expensive due to its self-attention, making it inefficient for smaller datasets without large-scale pretraining.
CLIP
The objective of CLIP's pretraining is to learn visual and textual representations by aligning images and their corresponding text descriptions in a shared embedding space.
CLIP uses image and text encoders to get embeddings and match those embeddings in embedding space using contrastive loss and negative sampled examples.
CLIP's primary advantage is its ability to align visual and textual data effectively within a shared embedding space, enabling zero-shot image classification and strong generalization to new, unseen concepts without additional labeled training data.
CLIP struggles with long-context text because it was trained primarily on short text-image pairs, making it less effective at extracting nuanced or contextualized meaning from longer textual inputs.
SAM
The objective of SAM's pretraining is to generate precise segmentation masks for any object in an image by learning from a large dataset of annotated images.
SAM (Segment Anything Model) is pretrained on image segmentation tasks, learning to generate precise masks for any object in an image. Then, the same model is used for fine-tuning on specific segmentation tasks to improve its accuracy in segmenting different objects across various domains.
SAM's strength lies in generating highly accurate segmentation masks universally applicable across diverse objects and domains, achieved through extensive training on a broad annotated image dataset, simplifying downstream fine-tuning and enabling rapid adaptation to specific tasks.
SAM requires significant computational resources and struggles with segmenting overlapping or occluded objects, sometimes producing incorrect masks in complex scenes.
DINOv2
The objective of DINOv2's pretraining is to learn self-supervised visual representations by maximizing the similarity between augmented views of the same image while maintaining uniqueness across different images.
DINOv2 is pretrained using a self-supervised learning approach, maximizing the similarity between augmented views of the same image while maintaining uniqueness across different images. Then, the learned visual representations are used for fine-tuning tasks like image classification, object detection, and other vision tasks.
Because of DINOv2's self-supervised objective, it captures robust and detailed information about images and provides great base for downstream tasks like object detection and semantic segmentation.
DINOv2 is highly dependent on the quality of its augmentations and lacks explicit supervision, which can lead to challenges in learning fine-grained details for certain tasks.
Stable Diffusion
The objective of Stable Diffusion's pretraining is to generate high-quality images from text prompts by learning the mapping between textual descriptions and image features using a diffusion-based generative model.
Stable diffusion takes image embeddings in latent space with some encoder model (VAE), adds gaussian noise with some policy and try to denoise it with defined time-stamps. As a result we get Denoising DIffusion Probabilistic Model, and we can give it a pure noise and based on our text description it generates an image.
The latent image distortion/distillation provides an opportunity to generate highly detailed and high-resolution images. The model's predictive power concentrates not on denoising each pixel but on denoising the image embedding, which has significantly lower dimensionality.
Stable Diffusion requires careful prompt engineering to achieve desired results, and its generation process is computationally intensive. It also struggles with compositional consistency across multiple generated images. It requires too much techniques to control generation process (Dreambooth, LoRA, ControlNet).
Flamingo
The objective of Flamingo's pretraining is to learn multimodal representations by jointly processing and understanding both text and images for tasks like visual question answering and captioning.
Flamingo is pretrained using a multimodal approach, learning to process both image and text inputs and align their representations in a shared space. Then, the model is fine-tuned on specific vision-and-language tasks like visual question answering, image captioning, and other multimodal reasoning tasks.
Flamingo excels in multimodal learning, effectively processing and aligning visual and textual inputs, thus greatly enhancing performance on vision-and-language tasks such as visual question answering, image captioning, and multimodal reasoning.
Flamingo's closed-source nature limits research accessibility, and it requires large-scale data and computational power, making it less practical for smaller organizations or researchers.
Sora
The objective of OpenAI's Sora is to enable large-scale vision and language models by learning to align and generate multimodal representations for a variety of tasks, such as vision-guided text generation, object understanding, and multimodal reasoning, using both images and text in an integrated manner.
Sora is pretrained using multimodal learning, aligning text and visual representations for tasks like image captioning and visual reasoning. Then, the model is fine-tuned on specialized tasks to improve performance in vision-language tasks across different domains.
Sora’s key advantage is its integration of multimodal learning, effectively aligning text and visual data. This alignment enhances performance in tasks requiring complex vision-language reasoning, such as image captioning, visual understanding, and reasoning.
Sora is not open-source, restricting experimentation and customization. Its reliance on multimodal data may also introduce biases and inconsistencies across different domains.
Gemini Pro Vision
The objective of Gemini Pro Vision is to enhance visual understanding and productivity by leveraging AI to analyze, interpret, and generate insights from images and videos, often applied in tasks like image classification, object detection, and automated visual reasoning.
Gemini Pro Vision is pretrained on a variety of image analysis tasks, learning to understand and interpret visual data in conjunction with other modalities. Then, it is fine-tuned for image classification, object detection, and automated reasoning in real-world scenarios.
Gemini Pro excels at interpreting and analyzing complex visual data, providing robust performance in real-world scenarios by integrating multimodal learning. It effectively enhances automated reasoning, image classification, and object detection tasks across diverse contexts.
Gemini Pro is proprietary and lacks public access, limiting its adaptability and customization. Additionally, it requires significant computational resources, making it less accessible for low-budget applications.
LLAVA
The objective of LLAVA model is to learn weights "translation" neural network layers, which take image embeddings embedded with the help of ViT and match to the embedding space of LLM that they chose for model training. They create synthetic dataset consisting from images and their corresponding explanations (for one
image we have several textual contexts).
LLAVA is pretrained by extracting image embeddings from ViT and aligning them with the latent space
of a language model. This alignment enables the model to process and understand visual information in a
textual context. The model uses a synthetic dataset, where each image is associated with multiple contextual explanations to enhance its visual-textual comprehension.
LLAVA's main advantage is its training dataset. It is constructed in a way that each image contains extensive textual descriptions, starting from item bounding box information and ending with detailed textual
explanations. This enables enormous reasoning capability and enhanced image understanding for the LLM.
LLAVA's main disadvantage is that its performance heavily depends on synthetic training data. The dataset needs to be diverse and highly descriptive, requiring deep prompt engineering for image descriptions. If it lacks diversity, the model may struggle with real-world scenarios.
See Lightly in Action
Curate data, train foundation models, deploy on edge today.
This section explores the core architectural building blocks of LVMs—starting with how they recognize and classify visual information, and progressing into how they integrate text, perform segmentation, and generate new visual content.
Image Understanding & Classification
One of the core capabilities of Large Vision Models (LVMs) is recognizing and categorizing what’s in an image.
This includes identifying objects, scenes, and patterns—tasks typically associated with image classification. LVMs are trained on large datasets to generalize across diverse visual inputs. At the heart of this capability is the Vision Transformer (ViT) architecture, which replaces traditional convolutional networks with a Transformer-based approach for superior scalability and flexibility.
ViT (Vision Transformer)
Figure 1: This figure illustrates the architecture of the Vision Transformer (ViT), where an input image is split into patches and linearly embedded, with an added class token. The sequence is then processed by a transformer encoder to produce a classification output through an MLP head.
The Vision Transformer (ViT) divides an image into fixed-size patches, flattens and embeds them, and adds positional encodings along with a special [CLS] token for classification. These tokenized inputs are passed through a standard Transformer encoder, followed by a Multi-Layer Perceptron (MLP) head that outputs classification scores.
This design leverages self-attention mechanisms to model relationships across the entire image, making it more flexible than CNNs and particularly effective on large-scale datasets. It forms the backbone for many advanced visual understanding systems.
ViT for Embedding Extraction
Beyond classification, ViTs are often used as feature extractors—producing dense visual embeddings that can be passed into other systems, like language models. In models such as LLAVA, the ViT generates image embeddings which are then projected into a shared space that the language model can understand.
To do this, a lightweight projection layer is trained to align ViT output with the language model’s input format. This enables powerful multimodal reasoning, where a model can interpret an image, connect it with text, and respond to natural language queries.
Multimodal Vision-Language Models
Some LVMs process visual data and text simultaneously, supporting tasks like image captioning, image-based question answering, and multimodal reasoning. Models such as Flamingo, CLIP, LLAVA, Gemini Pro Vision, and Sora integrate visual and textual data in a shared embedding space, enabling zero-shot classification, image-based question answering, and retrieval.
These vision-language models use contrastive learning, weak supervision, and fine-tuning techniques to align textual descriptions with visual tokens.
Flamingo
Flamingo is a multimodal model that bridges vision and language understanding. It enables large language models (LLMs) to process and generate text while also understanding images. The key innovation behind Flamingo is its Perceiver Resampler, which allows a pretrained LLM to incorporate visual data without extensive retraining.
Instead of modifying the LLM directly, Flamingo processes image representations from a frozen vision encoder (such as a Vision Transformer or a CNN) and maps them into a format that the language model can interpret.
Figure 2: This diagram presents a vision-language model architecture using a pretrained vision encoder with a Perceiver Resampler feeding into gated cross-attention-dense language model blocks. Interleaved visual-text inputs are tokenized and processed jointly to generate coherent language outputs.
The model is trained using contrastive learning and causal language modeling. In practice, Flamingo can handle few-shot learning by adapting to new image-text tasks with minimal examples. Given an image, it generates contextually relevant descriptions or answers questions based on the visual content.
Flamingo’s capability of describing images in few-shot and zero-shot settings are on high level, which helps to create a multimodal dialogue system.
CLIP
CLIP was created to close the gap between textual description and visual data. Its power relies on its simple zero-shot learning strategy. At its core, CLIP consists of two separate neural networks: an image encoder (often a Vision Transformer or a ResNet) and a text encoder (a Transformer-based model like GPT or BERT).
The image encoder processes visual inputs, while the text encoder processes natural language descriptions. Both representations are mapped to a shared latent space.
Figure 3:The image depicts a contrastive learning setup where separate encoders process images and text into embeddings that are compared in a similarity matrix. The model is trained to align corresponding image-text pairs by maximizing similarity scores in a joint embedding space.
To train CLIP, the model uses a contrastive learning approach.
Given a batch of image-text pairs, CLIP learns to maximize the similarity between matching pairs while minimizing the similarity between non-matching ones. Specifically, each image and text are projected into a joint embedding space using their respective encoders, and a cosine similarity score is computed. The training objective is to align image and text representations such that correct image-text pairs have the highest similarity scores.
Unlike traditional image classification models that rely on a predefined set of labels, CLIP offers a flexible and dynamic approach to image recognition. At inference time, instead of predicting a class from a fixed set, CLIP can classify images based on arbitrary natural language prompts provided by the user.
This is accomplished by encoding multiple text descriptions (e.g., "a cat," "a dog," "a car") and computing their similarity with the image encoding in a shared embedding space to determine the most relevant match. This open-ended classification capability makes CLIP highly adaptable to various downstream tasks without requiring task-specific retraining. When fine-tuned on previously unseen classes, CLIP leverages its contrastive learning framework to efficiently align textual descriptions with training images in the embedding space.
LLAVA
The authors of LLAVA found a way to join images to text with a very carefully designed dataset and ViT. Their main objective is to feed images to LLM with their corresponding text description and make LLM understand the image. They first take images with their bounding box information and corresponding description and prepare a dataset. Authors create conversation types with a given context, as shown in the picture. To create conversations, they used GPT-4 API, which already understands images and helped develop multimodal dataset.
Figure 4: This figure shows example multimodal annotations for images, including natural language captions, bounding boxes, and various types of model responses (conversation, description, reasoning). It highlights how diverse supervision enables training for complex vision-language understanding tasks.
Then, they pass the image through a ViT to get image embeddings. To make LLM understand the image embeddings, they train one projection layer responsible for translating the image embeddings to LLM-understandable embeddings.
Gemini Vision Pro is a model that again integrates vision and natural language processing, allowing it to process images, charts, videos, and text within a one framework. Unlike traditional vision-language models that rely on separate encoders, Gemini Vision Pro uses a joint Transformer-based architecture where both visual and textual data are mapped into a shared embedding space, enabling deep cross-modal reasoning. This means that unlike LLAVA, the embedding space of the model is received during one training, not adapting visual input to text embeddings.
The model processes images using a powerful Vision Transformer (ViT) backbone that extracts rich feature representations, which are then aligned with natural language inputs through a multimodal fusion mechanism. By leveraging a vast dataset of images, videos, and text, the model is capable of zero-shot and few-shot learning, allowing it to interpret complex charts, read scanned documents, generate captions, and answer visual questions without explicit fine-tuning.
During inference, Gemini Vision Pro excels at context-aware understanding, meaning it can analyze an image in relation to surrounding text, making it particularly effective for document analysis, accessibility tools, research automation, and AI-assisted data interpretation. Its ability to connect visual and textual information fluidly sets a new benchmark for multimodal AI systems, making it one of the most advanced vision-language models available today.
Sora
Sora is model that leverages latent diffusion, Transformers, and Variational Autoencoders (VAEs) to create realistic motion sequences from text, images, and video prompts. The process begins with training videos at high resolution, which are encoded through a VAE Encoder, transforming them into visual patches that represent the spatial structure of each frame. These patches then undergo a diffusion process, where noise is progressively added and later denoised to teach the model how to reconstruct realistic sequences.
To capture spatial dependencies, the model applies a Vision Transformer (ViT), embedding positional information and converting the patches into a latent representation. Video generation is further guided by conditional latent variables, incorporating multiple conditioning inputs such as images, video references, and extended text descriptions, which are refined using DALL·E 3 for re-captioning and GPT for text expansion. The core of Sora’s architecture is a Diffusion Transformer, a specialized Transformer optimized for diffusion-based video synthesis, allowing the model to maintain temporal consistency, object coherence, and realistic physics across frames.
Once processed, the latent representation is passed through a Linear Decoder and Reshaping module, which structures the output before being reconstructed into a video by the VAE Decoder (D). By operating in latent space instead of raw pixel space, Sora efficiently generates high-resolution, long-duration videos while preserving fine details and smooth transitions, making it a breakthrough in AI-driven content creation.
Combination of VAE, DiT, ViT and other architectures that are integrated in Sora helps them to ingest in the model's latent representation the physical information coming from the real world (training data from videos) enabling it to produce SOTA results.
Image segmentation and object detection
Segmentation and object identification require models to identify object boundaries and positions. SAM and DINOv2 demonstrate advanced capabilities in this area. SAM utilizes a vision transformer-based encoder, prompt encoder, and mask decoder to perform real-time visual data segmentation interactively. DINOv2 uses self-supervised learning to capture semantic structures for detection and segmentation.
These models enable precision in domains such as satellite images, quality inspection tasks, and navigation and obstacle avoidance.
SAM
The Segment Anything Model (SAM) model for universal image segmentation, designed to work across diverse objects and image types without requiring task-specific fine-tuning. At its core, SAM follows a three-stage architecture consisting of an Image Encoder, Prompt Encoder, and Mask Decoder.
Figure 5: The architecture demonstrates a vision-language instruction-following model where visual features from a vision encoder are projected and fused with language inputs in a decoder-only language model. The model generates responses conditioned on both image content and textual instructions.
The Image Encoder, built on a powerful Vision Transformer (ViT) backbone, processes the entire image once and generates a feature map, ensuring efficient segmentation for multiple queries on the same image. The Prompt Encoder allows users to guide the segmentation process by providing points, bounding boxes, or other inputs that indicate the target object. These prompts are embedded and aligned with the image features, directing the segmentation process.
Finally, the Mask Decoder takes both the encoded image and the processed prompts to generate an accurate segmentation mask, refining it iteratively through an attention-based mechanism. Trained on a massive dataset of over 1 billion masks, SAM can perform segmentation in a zero-shot manner, meaning it can identify and separate objects in unseen images without additional training. Unlike traditional models that require dataset-specific adaptation, SAM is highly interactive, allowing users to refine segmentation results dynamically, making it particularly valuable for applications in photo editing, medical imaging, robotics, and real-time vision systems.
DINOv2
DINOv2 is a self-supervised vision model designed to learn rich image representations without requiring labeled data. It builds upon the DINO (Self-Distillation with No Labels) framework, which trains Vision Transformers (ViTs) using contrastive learning. DINOv2 discovers semantic structures independently, unlike traditional approaches where data is explicitly labeled. This capability enables the model's training approach.
DINOv2 is trained using a student-teacher framework, where two networks learn to match feature representations. The teacher network generates consistent feature representations of images, and the student model learns to replicate these representations. This process helps DINOv2 develop a deep understanding of object structures, making it highly effective for object detection, segmentation, and retrieval tasks without additional fine-tuning.
DINOv2 excels in zero-shot and few-shot learning, making it a strong alternative to supervised models for vision tasks like clustering, segmentation, and image retrieval. Its ability to extract context-aware embeddings makes it particularly useful in scientific imaging, autonomous navigation, and medical diagnostics, where labeled data is scarce.
Image Generation
Stable Diffusion
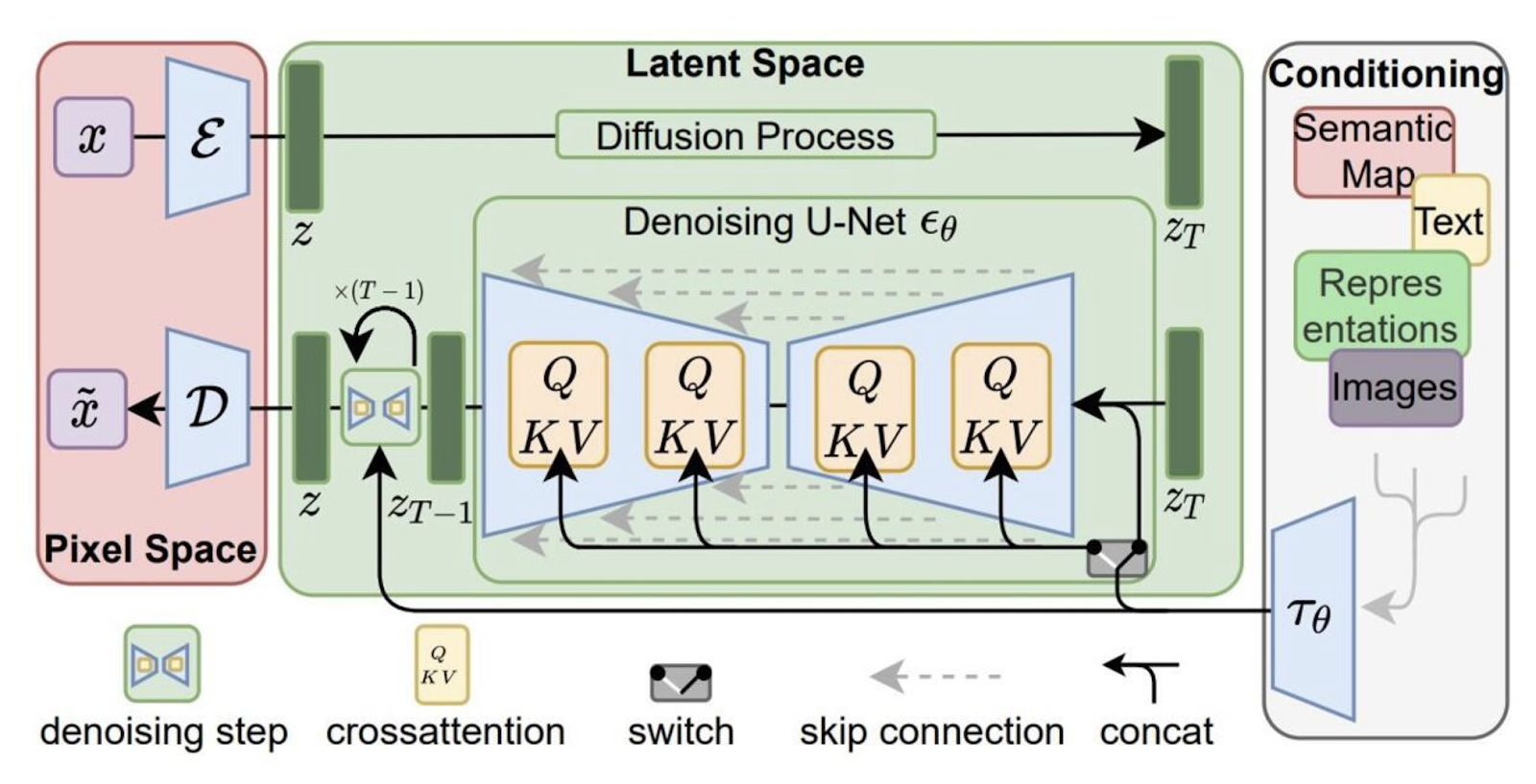
Stable Diffusion exemplifies text-to-image generation models that utilize latent space diffusion guided by natural language prompts. These large visual models can generate high resolution images from textual data by applying denoising techniques in compressed representations, making them ideal for tasks like video editing and content creation. They are also very good at photo and video enhancement and game development (i.e. landmark appearance generation) which makes them a very useful and flexible tool for production.
Figure 6: This diagram shows a latent diffusion model, where image generation happens in compressed latent space. An encoder maps the input image into latent space, where noise is added and removed via a denoising U-Net. Cross-attention and skip connections help reconstruct the image, which is finally decoded. The process is guided by conditioning inputs like text, semantic maps, or visual features encoded separately.
Key Features and Training Strategies for Large Vision Models
Large vision models leverage advanced training methodologies such as self-supervised learning, weak supervision, Low-Rank Adaptation (LoRA), and knowledge distillation. These models are pretrained on large-scale visual datasets and fine-tuned on domain-specific tasks such as diseases affecting crops, retinal images analysis, and tissue samples classification.
By using techniques like LoRA, deep learning models can be efficiently adapted for medical imaging, land cover analysis, and other niche visual tasks with limited data. Knowledge distillation also supports creating smaller models without sacrificing performance
One hallmark of LVM training is the use of massive datasets. For example:
Vision transformers in research were pretrained on JFT-300M (300 million images) or ImageNet-21k (14 million images across 21k classes) before fine-tuning to specific tasks.
CLIP was trained on 400 million image-text pairs gathered from the internet Such scale is crucial for it to learn a broad visual-language alignment.
Meta’s DINOv2 (a self-supervised ViT model) used 142 million images collected from the web for pretraining, without any human-provided labels. The model learns to generate its own training signal by making different augmentations of the same image have similar representations (knowledge distillation and clustering techniques).
Because labeling hundreds of millions of images manually is impractical, many LVMs rely on self-supervised learning or weak supervision.
Self-supervised learning
Self-supervised learning is an ML model training approach, during which the model is forced to complete and fill gaps, which are artificially added to the training data.
Currently, Deep Learning and GenAI are too advanced to use vanilla self-supervised learning, and we expect that the model, trained with this technique, will achieve state-of-the-art results. Instead, the authors of the above mentioned models mix self-supervised learning with other methods to train these models.
Models that use Self-Supervised Learning:
DINOv2 training pipeline involves self-supervised learning combined with a student-teacher approach. The student model learns to replicate the feature representations of the teacher network. It applies contrastive learning, meaning the model learns to distinguish between different images while also capturing semantic structures in an unsupervised manner. No labeled data is required, and the representations can be used for segmentation, object detection, and retrieval.
CLIP also uses self-supervised and contrastive learning, enabling amazing zero-shot image classification abilities during inference.
Stable Diffusion, with its predefined policy, adds noise to original image data and, during training, tries to denoise the images, making the training process self-supervised.
Lightly Train: Scalable Self-Supervised Learning for Production
For teams looking to scale self-supervised learning in real-world applications,Lightly Train offers a powerful, production-ready pipeline. It helps improve model performance using unlabeled data and integrates easily into existing training workflows.
Weak supervision is very similar to self-supervised learning, but has its own features and differences. Weak supervision is a machine learning paradigm where models are trained using noisy, incomplete, or imprecise labels instead of manually annotated ground-truth data.
Let’s briefly understand from our listed models which and how are using weak supervision.
CLIP - Uses large-scale image-text pairs scraped from the internet, which are weakly labeled (text captions may not perfectly describe images).
Flamingo - Uses pretrained models and weakly supervised vision-language pairs (e.g., noisy captions, web data).
LLAVA - Uses GPT-4-generated image-text conversation datasets, which are weakly supervised since they are AI-generated and may contain errors.
Gemini Pro Vision - Trained on large, weakly labeled datasets where textual descriptions may not precisely align with images.
Sora - Uses weakly supervised video-caption pairs and learned representations without explicit fine-grained labels.
Fine-Tuning and Adaptation (From General to Domain-Specific)
Generally, Large Multimodal Models’ training consists of pretraining and fine-tuning. After pretraining a generic large vision model, a common strategy is to fine-tune it on a specific task or domain.
Fine-tuning means taking the pretrained model and training it further on a smaller, targeted dataset, typically with supervised learning (task-specific labels), but starting from the pretrained weights speeds up convergence and often yields better performance due to the rich initialization.
However, traditional fine-tuning of a huge model for every new task can be resource-intensive. Emerging techniques include:
Prompting or Prompt Engineering
Text Hacks: If someone wants to adapt the output of a diffusion model like Stable Diffusion to match their specific needs, prompt engineering plays a crucial role in refining the generated images. By carefully selecting keywords, such as "ultra-detailed," "cinematic lighting," or "realistic textures," users can influence the quality and style of the output. Structuring prompts effectively by combining positive descriptions ("a luxury car in a futuristic city, photorealistic") with negative prompts ("no blurriness, no unrealistic textures") helps eliminate unwanted elements.
Adjusting Parameters: Additionally, adjusting parameters like the guidance scale ensures stronger adherence to the input text, while seed values allow for reproducibility. Iteratively modifying prompts, experimenting with word emphasis, and layering multiple descriptions enable users to fine-tune lighting, atmosphere, and object placement.
Low-Rank Adaptation (LoRA) and Adapters
If someone wants to adapt a diffusion model efficiently without retraining the entire network, LoRA (Low-Rank Adaptation) provides a lightweight and computationally optimal solution. Instead of fine-tuning all model parameters, LoRA injects trainable low-rank matrices into the model’s weight updates, significantly reducing the number of parameters that need adjustment. Mathematically, if the original weight matrix is W (with dimensions d by k), LoRA approximates the weight update as ΔW = A * B^T, where A has dimensions (d by r) and B has dimensions (k by r), with r being much smaller than both d and k. This means that instead of storing and updating a full d by k matrix, the model only optimizes two much smaller matrices, significantly reducing memory and computational overhead.
LoRA is optimal because it operates in the model’s intrinsic dimension, which refers to the minimum number of independent directions needed to capture the essential variations in a model’s learned representations. In deep learning, even though models have millions or billions of parameters, the effective number of independent variables governing their behavior is often much smaller. This is because most real-world data lies on a low-dimensional manifold within the high-dimensional parameter space, meaning that only a subset of directions significantly influence the model’s outputs.
LoRA leverages this by constraining updates to a subspace of low-rank adaptations, allowing the model to generalize better with fewer parameters. Additionally, LoRA keeps the original pretrained weights frozen, meaning that it can be easily toggled on or off, allowing rapid adaptation to different tasks without destroying prior knowledge. In essence, LoRA enables efficient fine-tuning by reducing parameter redundancy, minimizing computational costs, and maintaining adaptability, making it a powerful tool for customizing diffusion models and other large neural networks.
Knowledge Distillation
If someone wants to compress a large neural network while maintaining its performance, Knowledge Distillation (KD) provides an efficient way to transfer knowledge from a larger, more complex teacher model to a smaller, faster student model. Instead of training the student model from scratch with standard supervision, KD guides the student by mimicking the teacher’s outputs, making learning more structured and efficient. Mathematically, the student model is trained not just on ground-truth labels but also on the soft predictions of the teacher, where the loss function combines the standard cross-entropy loss with a distillation loss. Specifically, given a teacher’s probability distribution P_T and a student’s distribution P_S, the distillation loss is computed using Kullback-Leibler (KL) divergence:
Where Y represents ground-truth labels and α is a weighting factor balancing the two losses.
Knowledge Distillation is optimal because it leverages the intrinsic dimension of deep models, meaning that while large models learn complex, high-dimensional representations, much of their useful knowledge can be compressed into a lower-dimensional space. The student model does not need to match every parameter of the teacher but only captures the most informative patterns that influence decision-making. This allows for significant reductions in model size and computational cost while preserving performance on downstream tasks.
Additionally, because the student model learns from soft labels (continuous probabilities) rather than hard labels, it gains better generalization ability, making it more robust to noisy data. In essence, Knowledge Distillation enables efficient model compression by transferring structured knowledge from a teacher to a student, reducing computational demands while retaining strong predictive power.
Domain-Specific Large Vision Models
Domain-specific Large Vision Models (LVMs) are crucial for industries that require high precision and tailored AI solutions, such as manufacturing, healthcare, and AI-driven avatar generation, where general-purpose models may not perform optimally.
Unlike large-scale models trained on diverse internet data, domain-specific vision models are fine-tuned on specialized datasets, ensuring better accuracy, efficiency, and interpretability in industry-specific tasks. Landing AI, founded by Andrew Ng, exemplifies this approach through its LandingLens platform, which enables businesses to develop custom vision models for quality control and defect detection in manufacturing. By focusing on data-centric AI, Landing AI helps industries train models with limited yet high-quality labeled data, leveraging techniques like few-shot learning and weak supervision to improve performance in real-world applications.
Similarly, in AI-driven avatar generation, domain-specific LVMs such as DreamBooth allow users to fine-tune diffusion models to generate personalized images in a specific artistic style or based on user-provided reference images. LoRA (Low-Rank Adaptation) is commonly used in this context, enabling efficient fine-tuning of large diffusion models with minimal computational cost, making it ideal for adapting AI-generated avatars to brand aesthetics or personal likenesses. This domain-specific adaptation ensures that the model retains its general knowledge while incorporating fine details unique to a given subject.
Whether in industrial AI applications like Landing AI or creative AI solutions like DreamBooth, domain-specific LVMs optimize performance for specialized use cases, demonstrating the power of targeted AI adaptation beyond generic models.
Figure 7: (a) Stable Diffusion as a generic large vision model performing image generation via forward and reverse diffusion in latent space, conditioned on text and semantic inputs.(b) Domain-specific vision model for medical imaging, using a neural network to classify MRI scans based on learned visual features.
Zero-Shot and Few-Shot Learning Capabilities
From a training methodology perspective, it’s worth noting how LVMs achieve zero-shot/few-shot abilities:
Zero-shot learning in vision is often achieved by having the model learn a very general embedding or output space during pretraining, one that aligns with human-interpretable concepts (e.g., words). CLIP’s contrastive training is explicitly designed for zero-shot – at training time it sees many image-caption pairs, so at test time it can pair an unseen image with any text label. Another approach is training on meta-tasks so the model learns to adapt to new tasks (Meta AI’s Data2Vec and other multi-task learners).
Few-shot learning is enabled by models like Flamingo that were trained with a format allowing interleaved context. Flamingo’s training included feeding it examples and queries, teaching it to output answers after a few demos. So at inference, it naturally can ingest a few demos (images + text) and then generalize. In essence, the training objective was designed to mimic the few-shot scenario.
Applications and Use Cases of Large Vision Models
Large vision models are not just academic curiosities – they unlock a wide array of practical applications across industries. From healthcare diagnostics to autonomous vehicles, video editing, and deployment in realistic environments, LVMs are powering next-generation tools and experiences. Here we explore how LVMs are being applied, organized by the type of computer vision task.
Image Recognition at Scale
Image recognition and classification is a classic CV task, and LVMs have pushed its frontiers. A ViT or similar large model can classify thousands of object categories with high accuracy. For instance, Google’s ViT pretrained on JFT-300M and fine-tuned on ImageNet achieved top-tier accuracy >90%, surpassing EfficientNet ensembles but with a simpler pipeline.
In the real world, we can integrate ViT with identity verification platforms for some offices to track their employees’ presence and movement through facial recognition or badge scans. By leveraging ViT’s strong performance on image classification and recognition tasks, such systems can accurately verify identities in real-time, enhance security, and even automate attendance logging.
General image recognition
Large-scale models excel at recognizing a wide variety of everyday objects across scenes. These models classify broad categories such as animals, vehicles, buildings, tools, and more—even under occlusion, noise, or poor lighting. For example an AI-powered photo management app uses CLIP to index and tag millions of user-uploaded images by associating visual content with natural language queries. A user can search for “dogs playing in snow” or “sunset over water,” and CLIP enables retrieval across varied, previously unseen images without explicit category labels.
Fine-grained recognition
Fine-grained recognition requires identifying subtle differences between very similar-looking categories—like bird species, plant diseases, fashion brands, or medical anomalies. These tasks demand strong attention to local details and discriminative features. In a biodiversity project, DINOv2 is used to classify rare species of butterflies from citizen-submitted images. DINOv2, pretrained on a large unlabeled dataset, provides strong visual embeddings that enable fine-tuned classification on a limited labeled dataset—achieving high accuracy in identifying even closely related subspecies.
Facial recognition and people tagging
Facial recognition involves detecting and identifying individuals based on facial features, even across variations in age, expression, and lighting. People tagging in photos automates labeling of known individuals by comparing their face embeddings.
A social media platform uses Vision models like ViT + Stable Diffusion pipelines to not only detect and tag users in photos but also generate personalized avatars. ViT handles face detection and identification, while Stable Diffusion generates stylized profile images based on each user’s facial characteristics—offering both recognition and generative augmentation.
Object Detection and Segmentation in Domain-Specific LVMs
Object detection (identifying and locating multiple objects in an image) and segmentation (outlining the exact pixels of objects) are foundational for tasks like autonomous driving, robotics, and image editing. LVMs contribute in various ways:
Autonomous driving
Self-driving cars rely on real-time detection and segmentation of roads, vehicles, pedestrians, traffic signs, and lane markings under various weather and lighting conditions. Precision is critical for safety and navigation.
For example, DINOv2 provides high-quality dense features for real-time multi-object tracking and segmentation in dashcam footage. Combined with SAM, the system enables precise instance segmentation of cyclists and road barriers—helping the vehicle make safe, lane-aware decisions in complex urban environments.
Medical Image Recognition
Medical systems require accurate segmentation of organs, tumors, and abnormalities in scans like CT, MRI, and X-rays to assist with diagnosis and treatment planning. Precise localization is especially critical in early-stage disease detection.
In this case, ViT is fine-tuned with SAM segments lung nodules in chest CT scans with high pixel accuracy. The system highlights suspicious regions, supporting radiologists in early cancer detection while reducing false negatives in high-volume screening workflows.
Manufacturing and Industrial inspection
Factory inspection systems depend on real-time object detection and defect segmentation to identify flaws in assembly lines, such as surface scratches, missing components, or misalignments. For instance, SAM segments individual components on printed circuit boards, while CLIP classifies surface defects using natural language prompts like “cracked solder joint” or “missing resistor.” This enables zero-shot recognition of new defect types without the need for extensive retraining.
Aerial and Satellite Imaging
Satellite imagery and drone's visual input analysis involves detecting and segmenting structures like roads, buildings, and crop fields across large-scale environments. Challenges include varied resolution, occlusion, and changing terrain. For example, DINOv2 extracts dense features from satellite imagery to segment farmland boundaries and differentiate crop types. Coupled with Flamingo, the system enables users to query changes over time using natural language, such as “Which fields show signs of pest damage this month?”
Security & Surveillance
Modern surveillance systems rely on detecting people, vehicles, and unusual activities across multiple cameras, often with real-time alerting. Object segmentation helps focus on specific actors while reducing false alarms. For instance, ViT detects and segments individuals across surveillance footage, while LLAVA allows operators to interact with the video via natural language—for instance, asking, “Who entered the restricted zone after midnight?” and retrieving relevant visual frames for review.
Vision-Language Applications: Image Captioning, VQA, and Search
Because LVMs can bridge vision and language, they have enabled a host of applications where understanding images and generating or matching text is required:
Image captioning
Picture captioning involves generating natural language descriptions of visual content, which is useful for accessibility, social media, and automated reporting. For example, Flamingo generates rich captions like “A child playing with a golden retriever in a snowy park,” even when objects or actions are novel, thanks to its training across image-text pairs.
Visual question answering (VQA)
VQA allows users to ask natural language questions about an image, combining perception and reasoning. For example, LLAVA can answer “How many people are wearing safety gear in this construction site photo?” by interpreting both objects and context, making it valuable for industrial safety monitoring or educational tools.
Content-based image retrieval
Content-based image retrieval enables searching images using text (or vice versa), useful in e-commerce, digital asset management, and social platforms. For example, CLIP powers systems where users type “red vintage car on a mountain road” and retrieve matching visuals from massive image databases without manual tagging.
Multimodal assistants/agents
Multimodal assistants/agents combine vision, language, and reasoning to interact with users or environments in dynamic ways. For example, Gemini Pro Vision can analyze a complex chart or photo and follow up on commands like “Highlight the area with the highest sales” or “Describe the mood of this artwork,” making it ideal for knowledge work, creative tasks, and interactive user interfaces.
Generative Art and Content Creation
Large generative vision models have opened up new creative workflows across industries, from art to design to storytelling. These models translate text prompts into high-quality images or videos, enabling rapid prototyping and idea generation.
Text-to-Image Generation
Text-to-Image Generation allows users to create visual content from natural language prompts, revolutionizing illustration, design, and concept art. For example, Stable Diffusion can generate a “post-apocalyptic cityscape at golden hour” or a “cute robot baking cookies” in seconds, supporting artists, marketers, and game designers with limitless variations.
Image Inpainting
Image Inpaintingand Editing involves modifying parts of an image while preserving the rest—useful for object removal, background replacement, or imaginative alterations. For example, DALL·E allows users to erase a section of an image and type “replace sky with a galaxy,” seamlessly blending the generated region into the original scene.
Storyboarding and Animation Pre-visualization
Storyboarding and Animation Pre-visualization is accelerated by generative models that turn scripts or descriptions into visual scenes for film, advertising, and animation. For example, Sora takes prompts like “a dog running through a futuristic city at night” and generates short, coherent video clips, enabling rapid iteration during pre-production.
AI-Assisted Design and Prototyping
AI-Assisted Design and Prototyping enables the creation of product mockups, UI sketches, and design variations directly from descriptive prompts. For example, Gemini Pro Vision can interpret “a sleek, modern smartwatch interface with green health metrics” and generate high-fidelity visual designs that teams can build on.
Limitations and Challenges of Large Vision Models
Large Vision Models (LVMs) have unlocked powerful capabilities across vision and multimodal tasks.
However, they come with several limitations:
Cost and latency: Require significant compute resources for training and inference, making them expensive and sometimes impractical for real-time or edge deployment.
Data dependency: Performance relies heavily on large-scale datasets (often billions of image-text pairs), which are difficult to collect, maintain, and audit for quality.
Interpretability: It's often unclear how or why a model arrived at a specific prediction, complicating trust and debugging—especially in critical applications.
Bias: LVMs can reflect and amplify societal biases present in the training data, potentially leading to unfair or harmful outputs.
Reasoning limitations: They struggle with logic, commonsense reasoning, and multi-step tasks that require contextual understanding across time and modalities.
Limited grounded interaction: As highlighted in studies like “Vision language models are blind”, current models are not reliable agents for complex, grounded interaction.
Adaptation needs: Despite their versatility, LVMs often require fine-tuning or prompt engineering for optimal performance in specific domains or use cases.
Addressing these challenges is essential for building more robust, ethical, and accessible vision systems.
Future Trends and Research Directions for Large Vision Models
As LVMs evolve, new research directions are pushing the boundaries of scale, interactivity, and real-world applicability. Here are some key trends to watch:
Domain-Specific Foundation Models Expect vision models tailored for verticals like healthcare (e.g., a "BioViT" trained on medical images) or geospatial analysis (e.g., "GeoVLM" trained on satellite and GIS data). These would serve as specialized base models for industry-specific fine-tuning. Related:BioViL-T, Segment Anything in MedTech
Deeper Multimodal Fusion Models are moving beyond image+text to integrate audio, video, and temporal signals—enabling richer context and understanding across modalities.
Streaming Perception and Interactive Agents Future models will process live, real-time input—like robots continuously perceiving their surroundings and holding visual conversations. Related:Perceiver IO, RT-2
3D Vision and Scene Understanding LVMs will expand into 3D perception—learning from point clouds, meshes, and few-shot views to reconstruct scenes or generate 3D content from prompts. Related: NeRF, GNT
Lightly in Action: Accelerating Your Large Vision Model Development
Building and deploying Large Vision Models (LVMs) requires extensive, high-quality image datasets, efficient training strategies, and optimized inference workflows. Lightly simplifies this process, accelerating the pretraining and adaptation phases of your computer vision projects.
Here’s how Lightly can enhance your large vision model workflows:
LightlyTrain: Streamline your pretraining workflows using advanced embedding and clustering techniques. By automatically curating representative subsets of your visual data, LightlyTrain ensures your models learn more efficiently and robustly, reducing the amount of labeled data needed and accelerating time-to-deployment for domain-specific large vision models.
LightlyOne: Improve the quality of your datasets and significantly reduce labeling costs with intelligent data selection. LightlyOne automatically identifies and filters redundant or low-quality images, optimizing your datasets for superior model accuracy and performance in downstream tasks like object detection, segmentation, and zero-shot or few-shot learning.
LightlyEdge: Optimize the deployment of large vision models directly at the edge with powerful on-device inference and intelligent data filtering. LightlyEdge allows your computer vision applications to run faster and more efficiently, minimizing latency and bandwidth use, which is crucial for real-time industrial applications, autonomous driving, and other edge scenarios.
Get Started with Lightly
Talk to Lightly’s computer vision team about your use case.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

.png)


.png)













-min.png)
.png)
-min.png)