
Curating the Autonomous Driving dataset ZOD
Table of contents
Share blog post



Over the past years, we have seen exciting developments in the field of Autonomous Driving (AD). Machine Learning plays a pivotal role in autonomous vehicles, enabling the vehicle to learn from data and make predictions about the world around it. However, autonomous vehicles collect data continuously throughout a drive and not all collected data are equally useful to train a machine learning model. Furthermore, it is important to identify the most important data so that only these can be given for annotation.
Share blog post
Here is a short overview on data selection for autonomous driving.
- Why is smart data selection crucial for autonomous driving (AD)?
Autonomous vehicles continuously collect vast amounts of data, but not all of it is equally useful for training machine learning models. Identifying and annotating only the most important data is vital for efficiency, reducing annotation costs, and improving model performance. This is especially true given issues like class imbalance in real-world AD datasets.
- What is the Zenseact Dataset (ZOD)?
The Zenseact Dataset is a recently released, diverse autonomous driving dataset. The "Frames" subset used in this blog consists of 100,000 images collected over two years across fourteen different European countries, featuring varied weather conditions. It includes 2D bounding box annotations for objects like "Vehicle," "Vulnerable Vehicle," and "Pedestrian." Importantly, the dataset exhibits class imbalance, with significantly more "Vehicles" (e.g., 76.9% in the training set) compared to "Vulnerable Vehicles" (14.2%) and "Pedestrians" (8.9%).
- How does LightlyOne help with data selection for AD?
LightlyOne provides a data selection platform to intelligently curate subsets of AD data. The blog demonstrates training a YOLOv8 object detection model using only 10,000 selected images (out of 90,000 total training images) to achieve optimal performance and reduce annotation costs.
- What data selection strategies did they test, and what are their benefits?
The research evaluated several LightlyOne strategies, used individually or in combination:
- Diversity: Selects visually distinct images (based on embeddings) to avoid redundancy, particularly useful for continuous data streams like video frames where consecutive shots might be very similar.
- Class Balancing: Explicitly adjusts the distribution of object classes in the selected subset. For instance, uniform class balancing aims to have an equal representation of "Vehicle," "Vulnerable Vehicle," and "Pedestrian" in the selected set, contrasting with "input distribution balancing" which mirrors the original dataset's imbalance.
- Object Frequency: Prioritizes images that contain a high number of objects.
- Objectness Least Confidence Score: Uses the object detection model's prediction confidence to select challenging samples (e.g., occluded pedestrians) that the model struggles with, akin to active learning.
- What were the key findings regarding performance impact?
The experiments demonstrated significant improvements compared to random data selection:
- Uniform class balancing led to a significant increase in Mean Average Precision (mAP) because the model was no longer biased towards the majority "Vehicle" class, learning more effectively from the minority classes ("Vulnerable Vehicle" and "Pedestrian").
- All LightlyOne selection strategies, including Diversity, consistently resulted in better performance than random selection.
- Combining multiple strategies (e.g., Diversity with Object Frequency, Objectness Least Confidence, and Class Balancing) yielded even better results than using single strategies, allowing for fine-tuned data curation to meet specific needs and maximize annotation cost savings.
- What's the main takeaway for AD practitioners?
Intelligent data curation, as showcased by LightlyOne on the ZOD dataset, is a powerful approach for AD. By strategically selecting relevant, balanced, and diverse training data, developers can train more robust and accurate object detection models while significantly reducing annotation efforts and costs.
Over the past years, we have seen exciting developments in the field of Autonomous Driving (AD). Machine Learning plays a pivotal role in autonomous vehicles, enabling the vehicle to learn from data and make predictions about the world around it. However, autonomous vehicles collect data continuously throughout a drive and not all collected data are equally useful to train a machine learning model. Furthermore, it is important to identify the most important data so that only these can be given for annotation.
This is where LightlyOne comes in! You can use the data selection platform provided by LightlyOne to pick the most relevant data from your AD dataset. You can then only annotate the selected data and train the best possible machine learning model.
In this blog post, we will:
- Look into the Zenseact dataset [1] for autonomous driving.
- Explore different data selection strategies provided by LightlyOne to create subsets of the Zenseact dataset.
- Evaluate the performance of a yolov8 model [2] trained only on the selected subsets of the Zenseact dataset.
The Zenseact Dataset
The Zenseact dataset is a recently released Autonomous Driving dataset. We will use the Frames subset of Zenseact, which consists of 100k images, collected over two years in fourteen different European countries. Therefore, the data is very diverse and includes images in various weather conditions. The dataset also includes annotations of objects. These objects are annotated with a tightly fitting 2D bounding box indicated by the pixel coordinates of its four outermost points. In this blog post, we will consider the classes of objects “Vehicle”, “Vulnerable Vehicle”, and “Pedestrian”. You can see below an example image of the Zenseact dataset along with object annotations for “Vehicle”.

As can be expected, the classes are not balanced. Specifically, there are significantly more Vehicles, than Vulnerable Vehicles and Pedestrians. In the Figure below we show the class distribution in the training and validation set for the Zenseact dataset.

For many scenarios, you might want to focus more on vulnerable vehicles and pedestrians. Using balancing approaches we can change the distribution towards a more balanced setup. In what follows we will see how LightlyOne’s data selection strategies can take into account the distribution of classes in the selected subset.
Data Selection Strategies
Our goal with the data selection process that we will look into now, is to train the best possible object detection model while using only 10k annotated images.
Specifically, the process that we follow is composed of the following steps:
- Use the LightlyOne platform to select a subset of the data.
- Use the selected data only as the training set of the yolov8 model.
- Train the yolov8 model on the selected set.
- Evaluate the yolov8 model on the test set.
We use the following selection strategies alone or in combinations:
- Diversity: We use embeddings of the images to select the most diverse ones. In the case of the Zenseact dataset, this can be very relevant. Consider, for instance, the case where a car is stopped at a red traffic light. The consecutive frames that would be selected while the car is at a halt will be very similar to one another. The Diversity selection strategy will avoid the selection of multiple frames while the car is stopped.
- Class Balancing: We specify the desired distribution of classes at the selected set of images. For instance, we can choose to preserve the class distribution to be the same as in the entire training set. In the case of the Zenseact dataset this would mean that in the selected set of images, we would still have 76.9% vehicles, 14.2% vulnerable vehicles, and 8.9% pedestrians.
- Object Frequency: We prioritize the selection of images with many objects. In the case of the Zenseact dataset, this would be images with many pedestrians or vehicles as an example.
- Objectness Least Confidence Score: We use the score of the object detection prediction to select samples that are challenging for an object detection model. In the case of the Zenseact dataset, this would mean for example that images where pedestrians are occluded will be selected.
Experiments
We will now evaluate the different selection strategies. The experimental setup is the following:
- We use the Zenseact Frames dataset, which consists of 100k images, as described above. There are 90k training images and 10k test images.
- We train a yolov8 model [2] using only 10k selected images from the training set.
- We use two different training seeds.
- The first 5k images are selected randomly and the following 5k using the selection strategies Diversity, Class Balancing, Object Frequency, Objectness Least Confidence, and weighted combinations of these strategies.
- We train for 80 epochs using a Stochastic Gradient Descent [3] optimizer.
- We use two training seeds and report the mean and standard deviation of the Mean Average Precision in the test set.
How Does Class Balancing Impact the Model Performance?
Let us first look at how we can specify the class distribution in the selected set and how this will impact the performance of the yolov8 detection.
Since we have a significant class imbalance, one approach that would make sense would be to oversample the under-represented classes of “Vulnerable Vehicle” and “Pedestrian” and sample less from the most represented class of “Vehicle”. A simple way to do that is to enforce the classes in the selected set to follow a uniform distribution, as shown below:

In LightlyOne you can do this very simply using the following selection configuration:
1client.schedule_compute_worker_run(
2 selection_config={
3 "n_samples": 5000,
4 "strategies": [
5 "strategy": {
6 "type": "BALANCE",
7 "distribution": "UNIFORM",
8 }
9 ],
10 }
11)Another approach could be to preserve the class distribution to be the same as in the entire training set. Similarly, you can do this in LightlyOne as follows:
1client.schedule_compute_worker_run(
2 selection_config={
3 "n_samples": 5000,
4 "strategies": [
5 "strategy": {
6 "type": "BALANCE",
7 "distribution": "INPUT",
8 }
9 ],
10 }
11)This will result in a class distribution that is the same as the one shown in the first figure of this blog. In what follows we refer to this selection strategy as balancing according to the input distribution.
We show below the Mean Average Precision that we obtained when we trained the yolov8 model on the 5k randomly selected images, the 10k randomly selected images as well as on the 10k sets obtained with the LightlyOne balancing selection strategies. It can be seen that the selection according to the input distribution performs on par with random selection. This is expected as, on average across multiple seeds, random balancing should maintain the class distribution of the input. The balancing according to input still provides value, however, when the number of samples selected is very small or when only one subset of the entire training set can be created due to budget or time constraints.
Furthermore, it can be seen that data selection with uniform class balancing leads to a significant increase in the mean Average Precision. The reason for this is that the model does not get biased towards the majority class. Instead, due to the balance in the training data, it learns effectively also in the minority classes of “Vulnerable Vehicle” and “Pedestrian”.

To make this clear we show below the Precision-Recall curves for the data selection with balancing according to the input class distribution and according to the uniform class distribution. It can be seen that the class balancing strategy with data selection according to the input class distribution leads to higher Average Precision in the majority class “Vehicle” compared to the class balancing strategy with the uniform class distribution. On the contrary, the Average Precision for the minority classes of “Vulnerable Vehicle” and “Pedestrian” is significantly higher in the case of data selection with uniform class balancing. This is expected, as the model now sees more samples of these classes during training and delivers, as a consequence, a higher mean Average Precision(mAP) than in the case of data selection that preserves the input class distribution.

How Does Diversity Impact the Model Performance?
We now look into how we can use LightlyOne’s diversity strategy, as well as combinations of it with the other selection strategies. The diversity strategy can be performed on the images or the object crops. For this experiment, we chose to perform the diversity on the embeddings of the entire image as it could give us better variation for lighting and weather conditions.
We also investigate how we can combine the diversity selection strategy on the embeddings of the images with other selection strategies. Specifically, we consider combinations of the diversity strategy with the object frequency, the objectness least confidence, and the class balancing strategies. We show below the obtained results. It can be seen that in all cases the LightlyOne selection strategies lead to better performance than in the case where the data is selected randomly. Furthermore, adding the object frequency, the objectness least confidence and the class balancing strategies to diversity lead to better results than when diversity is used on its own.

The combination of three selection strategies can be performed in LightlyOne using the configuration below:
1client.schedule_compute_worker_run(,
2 selection_config={
3 "n_samples": num_images - total_images,
4 "strategies": [
5 {
6 # strategy to use prediction score (Active Learning)
7 "input": {
8 "type": "SCORES",
9 "task": "od_predictions",
10 "score": "objectness_least_confidence",
11 },
12 "strategy": {"type": "WEIGHTS"},
13 },
14 {
15 "input": {
16 "type": "EMBEDDINGS",
17 },
18 "strategy": {"type": "DIVERSITY", "strength": 0.6},
19 },
20 {
21 "input": {
22 "type": "PREDICTIONS",
23 "task": "od_predictions",
24 "name": "CATEGORY_COUNT",
25 "categories": [
26 "Vehicle",
27 "VulnerableVehicle",
28 "Pedestrian",
29 ],
30 },
31 "strategy": {"type": "WEIGHTS"},
32 },
33 ],
34 },
35)Notice how you can combine strategies with different strengths. For instance, in the configuration above, we use the Diversity strategy with a strength equal to 0.6. By combining the selection strategies provided by LightlyOne with different strengths you can select the optimal subset from your data according to your needs and benefit from significant cost savings in data annotation!
Conclusion
In this blog post, we illustrated how LightlyOne can be used to select the most relevant images from your autonomous driving dataset. We looked into different selection strategies and gave motivation about when they should be employed. Further, we showed how they can be configured in LightlyOne.
We used the Zenseact dataset as an example and performed experiments using a limited amount of data for training. This is relevant, as less data leads to a reduction in annotation costs. Through these experiments, we showed how data selection with LightlyOne can lead to significant improvement in the performance of a yolov8 model compared to the case of random selection.
Do you want to try out selection strategies to get the most out of your autonomous driving dataset? Check out our docs at LightlyOne and make the most out of your data!
Effrosyni Simou
Machine Learning Engineer
lightly.ai
References
[1] Alibeigi, Mina, et al. “Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[2] Ultralytics, “A state-of-the-art real-time object detection system”. https://docs.ultralytics.com . 2021.
[3] Sutskever, Ilya, et al. “On the importance of initialization and momentum in deep learning.” International Conference on Machine Learning. PMLR, 2013.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo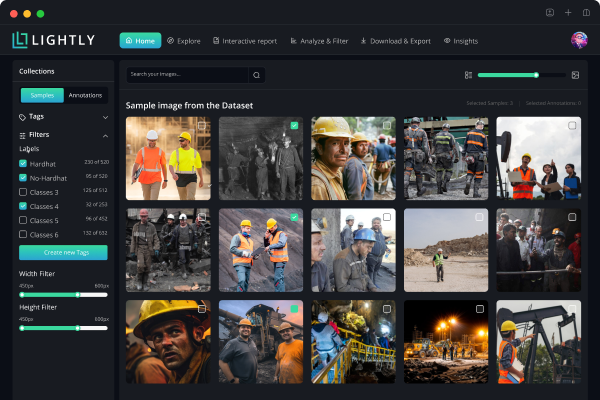

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.

.png)
.png)
.png)


