
12 Best Data Annotation Tools for Computer Vision (Free & Paid)
Table of contents
Share blog post



A practical 2026 guide to the 12 best data annotation tools for computer vision — covering both paid platforms (Roboflow, Labelbox, SuperAnnotate, Scale AI, Encord, V7 Labs) and open-source tools (CVAT, Label Studio, LabelMe, MONAI Label, Make Sense, LightlyStudio). Includes annotation types, AI-assisted labeling trends, comparison tables, pricing, and how to choose the right tool for your team and use case.
Share blog post
The data annotation market is expanding rapidly as demand for high-quality training data grows across computer vision, generative AI, and multimodal foundation models. Foundation models like SAM 3 have reshaped the tooling landscape, making AI-assisted labeling standard. Here are the 12 best data annotation tools for computer vision in 2026 — paid and open-source — and how to choose the right one.
Data annotation is the process of labeling raw images, videos, and 3D point clouds with structured information—object boundaries, class labels, keypoints, and more—so that computer vision models can learn from them. Without consistently labeled training data, even well-designed machine learning models produce unreliable results in production.
The demand for labeling tools is growing rapidly alongside the broader expansion of computer vision and AI applications. According to Straits Research, the data annotation market is expected to grow from USD 3.63 billion in 2025 to USD 23.82 billion by 2033. This growth is driven by surging enterprise demand for high-quality training data across generative AI, autonomous systems, and multimodal foundation models.
The tooling landscape itself has changed considerably. Foundation models—particularly Meta's Segment Anything Model family, now at SAM 3 as of late 2025—have become standard inside data annotation tools, reducing manual labeling effort significantly. Active learning, automated pre-labeling, and AI-assisted annotation are now table-stakes features rather than premium differentiators. And the boundary between annotation tools and broader data management platforms has blurred: most serious data annotation platforms now bundle curation, versioning, quality assurance, and model evaluation alongside basic labeling.
This article compares paid and open-source data annotation tools for computer vision, covering their current features, honest trade-offs, and practical fit for different teams and use cases. Whether you are looking for an image annotation tool, a video labeling platform, or a web-based tool for quick prototyping, understanding the key differences between available labeling tools will help you make a faster and more confident decision.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
What Is Data Annotation?
Data annotation is the process of adding meaningful labels to raw data—images, video frames, point cloud data, sensor data, or other inputs—to make it understandable and usable for machine learning model training. These labels tell the model what it is looking at: the class of an object, its spatial boundaries, its pose, or its pixel-level membership in a category.
In supervised learning, annotated data is the primary training signal. The labeling process directly determines what patterns the model learns. Poorly annotated data introduces noise that degrades model performance regardless of architecture quality. A self-driving system that misclassifies a pedestrian because of inconsistent training data annotations is not an architecture problem; it is a data quality problem.
The Role of Training Data in Machine Learning
High-quality training data is what separates a machine learning model that works in controlled tests from one that performs reliably in production. The data labeling process defines the ground truth that machine learning algorithms learn from. For computer vision specifically, this means consistently labeled bounding boxes, segmentation masks, and keypoints across thousands or millions of image and video frames. Errors compound: a model trained on inconsistently annotated training data will generalize poorly, regardless of architecture or compute budget.
The data labeling process typically involves:
- Defining an ontology (the classes, data types, attributes, and relationships to label)
- Assigning data annotation tasks to human annotators or automated pipelines
- Reviewing and quality-checking completed annotations
- Exporting annotated data in the format required for model training
Data Labeling vs. Data Annotation
The terms data labeling and data annotation are often used interchangeably, but there is a subtle difference. Data labeling typically refers to assigning high-level class tags to entire images or data records—for example, labeling an image as "cat" or "dog." Data annotation refers more broadly to any structured markup of raw data, including bounding boxes, segmentation masks, keypoints, and other spatial or semantic metadata. In practice, most labeling tools handle both tasks within the same platform.
Types of Data Annotation for Computer Vision
Different computer vision tasks require different data types and annotation approaches. Choosing a data annotation tool or video annotation tool that supports your specific annotation types is essential before evaluating any platform.
Bounding Boxes
Bounding box annotation involves drawing bounding boxes around objects in an image or video frame. This is the most common data annotation type for object detection and is supported by virtually every data annotation platform. Drawing bounding boxes is fast, and most labeling tools offer an intuitive user interface with keyboard shortcuts for high-throughput workflows.
Semantic Segmentation
Semantic segmentation assigns a class label to every pixel in an image, grouping all pixels of the same class together. This image segmentation approach is used for scene understanding in autonomous driving, satellite imagery analysis, and medical computer vision applications.
Instance Segmentation
Instance segmentation goes beyond semantic segmentation by distinguishing individual object instances within the same class. Semantic and instance segmentation are more labor-intensive than bounding boxes, which is why data annotation tools using SAM-based models have significantly reduced annotation time and improved annotation efficiency. Accurate annotations for these data types require careful quality control.
Image Classification
Image classification annotates an entire image with one or more class labels, without marking specific object locations. It is the simplest data annotation type and is used for tasks like defect detection in manufacturing or content moderation for computer vision systems.
Keypoints and Landmarks
Keypoint data annotation marks precise points on specific object features—joints for human pose estimation, corners for geometric objects, or landmarks for facial recognition. This annotation type is critical for robotics, sports analytics, and medical imaging computer vision applications.
Polygon, Polyline, and Box Annotation
Polygons and polylines offer more precise boundaries for irregularly shaped objects. Box annotation with rotatable bounding boxes is common in aerial imagery and text detection computer vision tasks. Labeling objects with polygon annotations produces higher-quality training data for image segmentation models.
3D Point Cloud Data and Object Tracking
For autonomous vehicles, robotics, and industrial computer vision, annotating 3D point cloud data from LiDAR sensors requires dedicated data annotation tools. Annotation data types include 3D cuboids and semantic labels applied to point clusters. Object tracking in video annotation maintains consistent object identities across frames—a critical capability for motion analysis and autonomous driving. A capable video annotation tool propagates annotations across frames automatically, dramatically improving annotation efficiency on long video sequences.
Manual Annotation vs. Automated Annotation
Manual Annotation
Manual annotation relies on human annotators labeling each image or video frame directly. It is the most accurate data annotation approach for complex or ambiguous scenes, and remains essential for edge cases, quality review, and producing the valuable training data that automated systems struggle to label correctly. A user-friendly interface matters significantly—data annotation tools with intuitive controls reduce annotator fatigue and error rates at scale.
Automated Annotation and AI-Assisted Labeling
Automated annotation uses machine learning algorithms and AI models to generate labels without human input. Foundation models like SAM 3 can produce polygon masks with a single click or text prompt. Pre-trained object detection models can generate initial box annotation results across an entire dataset in minutes, replacing hours of manual data annotation.
AI-assisted labeling combines both: the model suggests annotations and a human reviews, corrects, and approves them. This is the approach most production data annotation workflows use in 2026—it delivers the annotation efficiency of automation with human oversight for accurate annotations. The right data annotation platform should support configurable workflows blending automatic annotation and manual review to match your quality requirements.
Why Data Annotation Quality Matters
The model performance and reliability of any computer vision system is directly tied to the quality of its training data. Well-annotated training data enables data scientists and ML engineers to build machine learning models that generalize to real-world variation. Inaccuracies in the data annotation process produce models that fail on edge cases—a serious concern in safety-critical applications like medical imaging, autonomous driving, and industrial computer vision.
Beyond accuracy, data annotation also affects cost. The most significant annotation efficiency gains come from three practices: AI-assisted annotation (using foundation models to pre-label data for human review), active learning (prioritizing the unlabeled samples most likely to improve machine learning models), and near-duplicate filtering (removing redundant samples before they reach the annotation queue).
Best Data Annotation Tools: Paid Annotation Tools
Paid data annotation tools offer scalable infrastructure, built-in quality control workflows, role-based access controls, and dedicated support. Key functional advantages include:
AI-assisted labeling: Most paid data annotation tools now integrate SAM 2 or SAM 3 for interactive segmentation, plus model-assisted pre-labeling for automated annotation at dataset scale.
Quality control: Inter-annotator agreement, consensus scoring, benchmark label comparisons, and multi-stage review queues maintain consistent, accurate annotations across large computer vision datasets.
Collaboration and project management capabilities: Role-based task assignment, reviewer stages, commenting, and audit logs support large data annotation teams. Many paid annotation platforms include project management capabilities for tracking progress across multiple datasets and data types.
Automation features: Automated interpolation, object detection pre-labeling, and ML-based quality checks reduce manual effort and improve annotation efficiency across the data labeling process.
Security and compliance: Enterprise data annotation tools typically offer SOC 2, ISO 27001, HIPAA, and GDPR certifications that self-hosted tools require additional engineering to achieve.
Always pilot any paid data annotation platform with your own data before signing a contract—pricing models, feature coverage, and data format lock-in vary considerably.
1. Roboflow
Roboflow is an end-to-end computer vision platform covering dataset import, data annotation, model training, and deployment. Its image annotation tool supports object detection, classification, and instance segmentation across a wide range of data types. With over one million users, it is one of the most widely adopted labeling tools in the computer vision community.
Key features include Label Assist (suggestions based on your previously labeled training data) and Auto Label (automated annotation using Grounding DINO and SAM). Roboflow Universe, its public model and dataset repository, contains over 750,000 datasets and 575+ million labeled images — most valuable data for bootstrapping computer vision projects with limited initial annotations. It also integrates with AI and machine learning frameworks including Ultralytics and HuggingFace.
Pricing: Free for public projects; paid plans for private data start around $249–$299/month. Confirm current rates directly.
Limitations: High memory usage reported on large datasets. Free tier restricts private data. Data annotation tooling is less mature than dedicated platforms for complex image segmentation or medical computer vision workflows. Support responsiveness at lower tiers receives mixed reviews.
2. Labelbox
Labelbox has evolved into a generative AI data platform—supporting images, video, text, audio, and documents in a unified data annotation workspace. For computer vision specifically, it provides standard annotation types across multiple data types, model-assisted labeling via its Model Foundry, and a node-based workflow editor for multi-stage review pipelines. Its "Alignerr" community provides on-demand expert annotation services.
What's new (2026): Labelbox acquired Upcraft in February 2026 to expand its expert workforce. Frontier model integrations for automated annotation (including Claude, Gemini, and OpenAI models) added to Model Foundry. Expanded multimodal evaluation editor for generative AI training data use cases.
Pricing: Free tier (500 LBU/month); Starter at $0.10/LBU; Enterprise custom pricing.
Limitations: Pricing transparency is a recurring concern—get a written quote based on actual volume. Learning curve for complex workflow configuration. Limited 3D/LiDAR support—verify with the vendor.
3. SuperAnnotate
SuperAnnotate is ranked highly for usability and workflow flexibility among paid annotation platforms. It is a computer vision and NLP data annotation platform emphasizing annotation quality and managed labeling services. SuperAnnotate uses AI-assisted annotation to accelerate the labeling process and improve annotation efficiency across diverse data types. Its image annotation tool covers object detection, classification, image segmentation, pose estimation, and OCR. Video data annotation supports object tracking, instance segmentation, and action detection.
The platform includes AI-assisted annotation, customizable ontologies, a Python SDK, and a marketplace of vetted annotation teams for large-scale data labeling. It is backed by NVIDIA and Databricks Ventures, and serves enterprise customers including Databricks, IBM, and ServiceNow.
Pricing: Limited free startup plan; Pro and Enterprise plans with custom pricing.
Limitations: Slow loading on large datasets reported. Point cloud data annotation is a noted gap. Video annotation tooling is considered less mature than dedicated video annotation tools.
4. Scale AI
Scale AI is a large-scale platform focusing on hyperscale, high-volume annotation programs with a heavily managed workforce — primarily serving enterprise AI labs, autonomous vehicle teams, and government clients. Its Data Engine covers collection, curation, annotation, RLHF, and model evaluation across images, video, text, sensor data, and 3D point cloud data types.
What's new (2026): Meta acquired a 49% non-voting stake in Scale AI in June 2025 for approximately $14.8 billion. Scale operates independently under a new CEO (Jason Droege). Scale Labs—an expanded research and evaluation division—launched March 2026. Scale has expanded its Data Engine into robotics and physical AI.
Pricing: Custom enterprise contracts only. Not designed for small teams.
Limitations: Pricing opacity is a consistent complaint. Quality can vary with crowdsourced annotators. Scale's workforce practices have faced legal scrutiny, including contractor lawsuits alleging wage theft and misclassification (2024–2025).
5. Encord
Encord is an end-to-end data annotation platform supporting images, video, audio, text, HTML, and DICOM medical imaging in a single workspace. Data annotation types include bounding boxes, polygons, polylines, keypoints, bitmasks, and 3D cuboids for point cloud data and object tracking across video frames. Its video annotation tool preserves temporal context, enabling consistent object tracking and annotation efficiency across long video data sequences.
What's new (2026): SAM 3 integration (early access); cloud-synced folder support; comments and issues on data annotation tasks (beta); synchronized DICOM series navigation; numerical ontology attribute types.
Pricing: Custom, quote-based. Free demo available.
Limitations: Pricing is opaque until you engage sales. On-premise deployment adds setup complexity. Platform breadth can increase onboarding time for straightforward computer vision projects.
6. V7 Labs (Darwin)
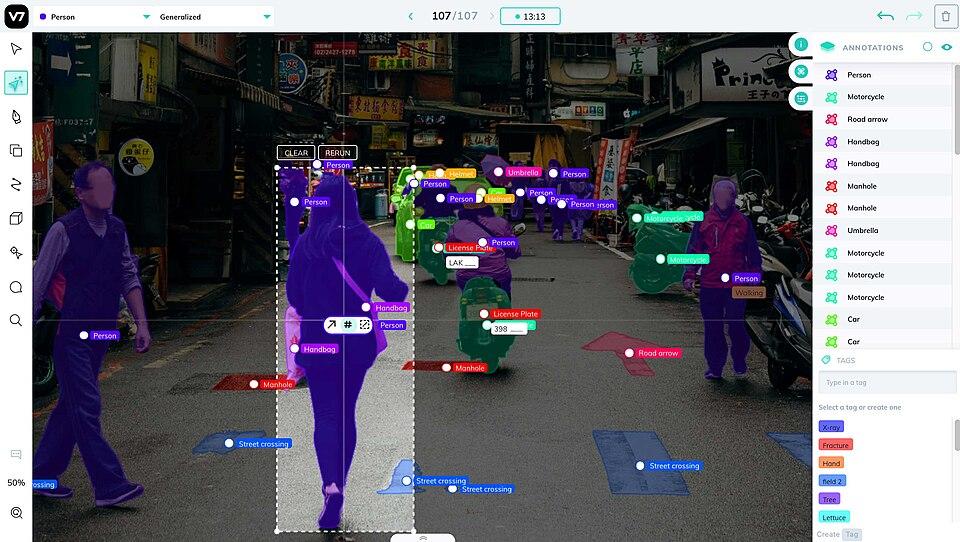
V7 Labs offers Darwin, a specialized data annotation platform with particular strength in medical imaging and video annotation. It supports images, video, DICOM (including MPR views and oblique views), NIfTI, and WSI data types.
SAM 3 was integrated in late 2025, adding text-based automatic class detection across all instances simultaneously. The video annotation tool includes improved object tracking continuity and new Split/Unify tools for correcting identity errors across video data without re-labeling entire sequences.
What's new (2026): SAM 3 with text-based class detection; custom Dataset Labels for improved dataset organization (February 2026); improved video object tracking identity persistence.
Pricing: Free tier; subscription and usage-based paid plans. Confirm current rates directly.
Limitations: Occasional lag on large video data sets at peak usage. Automated annotation performs less reliably on low-contrast image regions. Documentation sometimes lags behind fast product updates.
Paid Data Annotation Tools: Comparison Table
Choosing the Right Paid Data Annotation Tool
Budget and pricing model: Per-image billing suits smaller, project-based work. Custom enterprise agreements suit ongoing, high-volume data annotation operations. Always get a written quote based on your actual expected volume.
Data types and annotation coverage: If you need 3D point cloud data, DICOM medical imaging, or high-volume video annotation with object tracking, verify each platform's depth with a real pilot project. Not all data annotation tools handle all data types equally.
Model training requirements: Test your export workflow with a representative data sample first. Most data annotation tools export COCO, YOLO, and PASCAL VOC, but proprietary schemas and data format structures vary.
Security and compliance: For healthcare, government, or regulated industries, verify certifications rather than assuming them.
Best Data Annotation Tools: Open-Source Annotation Tools
Open-source data annotation tools eliminate licensing costs and give teams full control over data, infrastructure, and the annotation process. These open source tools are strong alternatives to existing paid tools, particularly for teams with strong engineering capacity or strict data residency requirements. The open source tool ecosystem ranges from simple web-based tools for quick image annotation to full-featured platforms supporting advanced features like 3D point cloud annotation, object tracking, and AI-assisted labeling.
Key advantages of open source tools: no per-seat or per-image fees; full control over data types and storage; source code transparency; active communities for widely-used labeling tools.
Key limitations: self-hosting requires infrastructure management; collaboration features are weaker than paid data annotation platforms; security hardening is the team's responsibility.
1. CVAT
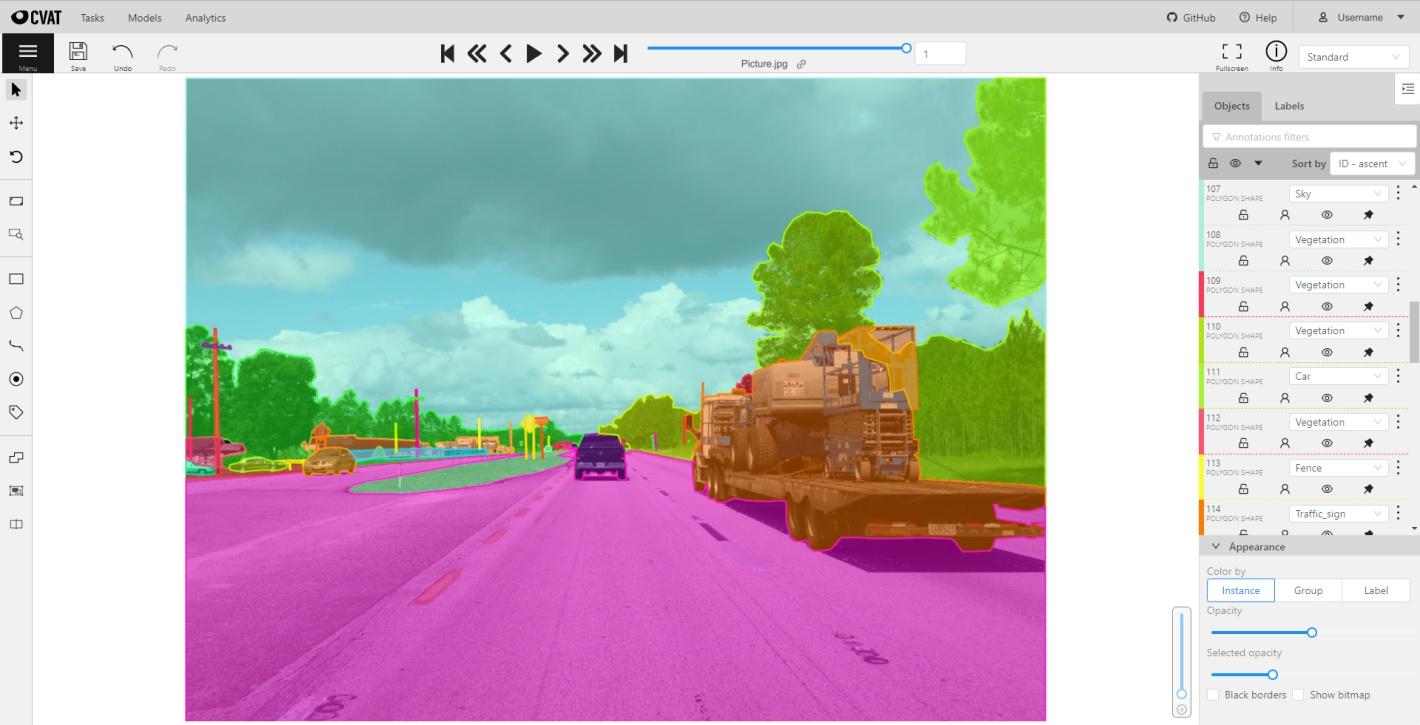
CVAT (Computer Vision Annotation Tool) was originally developed by Intel and is now maintained by CVAT.ai Corporation. It is the most feature-complete open source data annotation tool available for computer vision, supporting bounding boxes, polygons, polylines, keypoints, cuboids, skeletons, 3D point cloud data, and video annotation across all major data types. CVAT is a leading open source tool for high-precision computer vision tasks, with advanced features like object tracking interpolation and integration with models like YOLO. Available as an online annotation tool at cvat.ai (free tier: up to 10 tasks, 500 MB) and as a self-hosted deployment via Docker Compose.
What's new (2026): SAM 3 integration (November 2025); AI Agents framework for agentic automated annotation; improved analytics with per-label shape counts and time tracking; improved 3D point cloud annotation stability; bulk actions; keyboard shortcut customization. Current release: v2.59.1 (March 2026).
Limitations: Steeper learning curve than simpler data annotation tools. Free cloud tier has strict limits. Self-hosted deployment requires Docker familiarity.
2. Label Studio
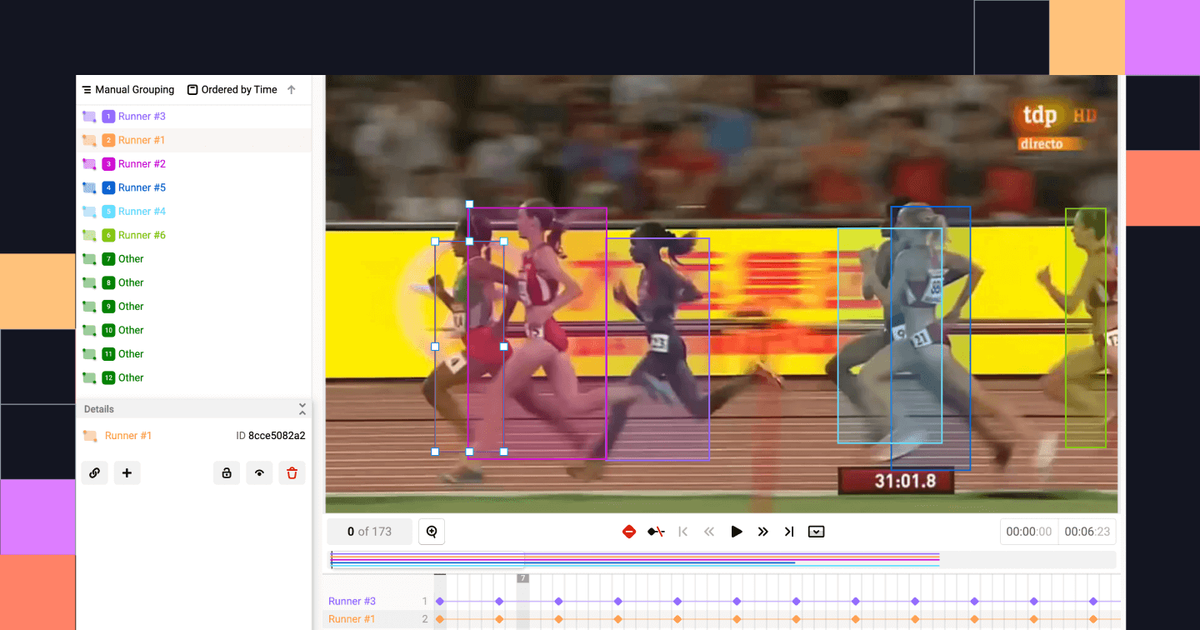
Label Studio (by HumanSignal) is known for being extremely flexible and multimodal, offering custom interface templates and a REST API for MLOps integration. It is an open source, web-based data annotation platform supporting images, video, text, audio, and time-series data types. It also functions as a capable text annotation tool supporting named entity recognition, sentiment labeling, and relation extraction — making it practical for teams that need both computer vision and natural language processing data annotation in a single platform. Doccano is another dedicated open source text annotation tool worth considering for NLP-focused teams needing named entity recognition, sentiment analysis tagging, and multilingual support, though it lacks image annotation capabilities.
Pricing: Open-source (Apache-2.0). Label Studio Enterprise adds team management, SSO, and advanced QA features at custom pricing.
Limitations: Interface configuration has a learning curve. Collaboration features in the open-source version are limited. Large datasets may require infrastructure tuning to maintain annotation efficiency.
3. LabelMe

LabelMe is an open-source image annotation tool originally developed by MIT's CSAIL. It supports polygons, rectangles, circles, lines, keypoints, and image segmentation masks across standard computer vision data types, with export to PASCAL VOC and COCO formats. Browser-based and requires no installation. Built-in AI models reduce manual data annotation effort on common objects.
Limitations: No collaboration features. Manual data upload and export required. Not suitable for teams, large datasets, or multi-stage data annotation workflows.
4. MONAI Label
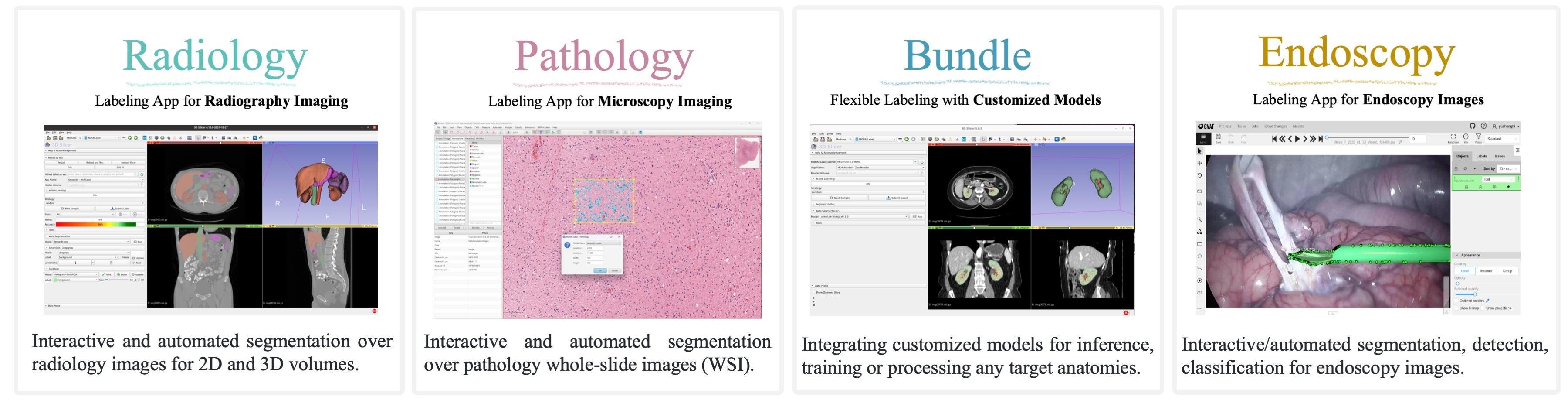
MONAI Label is an open-source framework purpose-built for medical imaging data annotation. Its active learning module continuously updates AI models as annotators provide feedback, progressively reducing manual data annotation workload and improving annotation efficiency over time. It integrates with third-party viewers including the Digital Slide Archive (DSA) and CVAT.
Limitations: Purpose-built for medical computer vision only. Not a general-purpose data annotation tool. Requires familiarity with clinical imaging data types and MONAI-compatible infrastructure.
5. Make Sense
Make Sense is a browser-based, open-source online annotation tool licensed under GPLv3. No installation required. Supports bounding boxes, lines, keypoints, and polygons across standard image data types, with export to YOLO, VOC XML, VGG JSON, and CSV formats. Integrates with Roboflow for AI-assisted labeling, making it a convenient entry point for teams evaluating existing data annotation tools before committing to a paid platform.
Limitations: No built-in automated annotation features. No project management capabilities. Limited to image data types. Not suitable for team workflows or large-scale data annotation.
6. LightlyStudio
LightlyStudio is Lightly's unified open-source platform for labeling, curation, QA, and dataset management — free to get started and open-source at its core. Unlike traditional annotation-only open source tools, LightlyStudio connects data curation and labeling in a single environment, helping ML teams select the most valuable samples before they reach the annotation queue.
The platform supports image, video, audio, text, and DICOM data types. Key features include built-in annotation and QA tools, embedding-based data exploration, near-duplicate detection, active learning pipelines that surface the most informative samples for labeling, dataset versioning, team collaboration with role-based permissions, and a plugin system for extensibility (v0.4.6, December 2025). LightlyStudio is designed for both ML engineers — via a Python SDK, API, and open-source standards — and labelers and project managers, who benefit from its user-friendly interface and performance tracking.
The platform deploys on-prem, hybrid, or in the cloud, and is ISO 27001 certified. It is trusted by organizations including Bosch, Meta, IBM, and ETH Zurich. Migration from existing tools including Encord, V7 Labs, Roboflow, and Ultralytics is supported.
Pricing: Free and open-source. Enterprise features and hosted deployment available — contact Lightly for details.
Limitations: The hosted cloud version is still in development; teams requiring a fully managed SaaS experience should contact Lightly directly.
Open-Source Data Annotation Tools: Comparison Table
Choosing the Right Open-Source Data Annotation Tool
Maintenance status: Verify any open-source data annotation tool is actively maintained before adopting it. Tools that become unsupported create technical debt and security exposure over time.
Feature requirements: CVAT is the most capable open-source option for serious computer vision data annotation tasks including video annotation and 3D point cloud data types. Label Studio is the strongest choice for multi-modal workflows combining image and text annotation. LabelMe is ideal for research-scale data annotation tasks.
Technical overhead: Self-hosting CVAT requires Docker familiarity. If your team lacks this capacity, CVAT's free hosted tier or a paid data annotation platform may be more practical.
General Factors When Choosing a Data Annotation Tool
Data Types and Annotation Format
Verify the data annotation tool supports your specific data types and annotation formats—semantic segmentation, instance segmentation, image segmentation masks, 3D cuboids, keypoints, and so on. Verify that data format exports match your training pipeline (COCO, YOLO, PASCAL VOC, or custom).
Video Annotation Tool and Object Tracking
Pay close attention to each platform's video annotation tool if your project involves video data. Key capabilities include object tracking across frames, automated interpolation between keyframes, and tools for correcting tracking errors without re-labeling entire sequences.
Text Annotation Tool and Multi-Modal Support
Some data scientists also need a text annotation tool alongside computer vision capabilities—for projects combining image segmentation with natural language processing, or building multimodal training data covering images, video data, and text.
Training Data Quality and Model Training
Consider how annotated training data flows into model training. Test your export workflow with a representative data sample first. Most data annotation tools export standard data formats, but proprietary schemas can create pipeline friction.
Quality Control and Accurate Annotations
For production training data, QA features—inter-annotator agreement, review stages, gold label benchmarking, annotation accuracy tracking—matter significantly. Skipping quality control consistently produces lower-quality training data that reduces model performance over time.
Deployment and Integration
Consider whether the data annotation tool is cloud-based, self-hosted, or supports on-premise deployment. For teams with strict data governance requirements, on-premise deployment may be essential.
Reducing Labeling Costs Through Data Curation: LightlyStudio and LightlyTrain
A complementary approach to data annotation efficiency focuses on which data you label. Data curation selects the most informative, diverse, and non-redundant samples from your raw data before they enter the annotation queue, reducing the total volume of training data that requires labeling without sacrificing model performance.
LightlyStudio
LightlyStudio is covered in full in the open-source tools section above. Its curation-first approach — selecting the most valuable samples before labeling begins — is what sets it apart from annotation-only tools. Teams can use it standalone or pair it with LightlyTrain for a complete data-to-model pipeline.
LightlyTrain
LightlyTrain (launched 2025) is a framework for self-supervised pretraining, fine-tuning, distillation, and automated annotation on domain-specific visual data. It supports YOLO (v8, v11), ViTs, RT-DETR, DINOv3, ResNet, and Faster R-CNN. Pretraining requires no labeled training data, making it valuable for computer vision domains where annotated data is scarce. LightlyTrain 0.14.0 (early 2026) added PicoDet models for real-time object detection on edge devices, tiny DINOv3-based segmentation models, and FP16 ONNX/TensorRT export. Licensed under AGPL-3.0 for open-source use; commercial licensing available.
LightlySSL
LightlySSL is Lightly's open-source self-supervised learning research framework (MIT license) for experimenting with SSL methods on image data types.
Conclusion
Choosing between paid and open-source data annotation tools depends on your project's actual requirements, team size, and budget. A few practical guidelines for 2026:
For beginners and small projects: CVAT's free tier or LabelMe covers most basic computer vision data annotation needs at no cost. Label Studio is the best open-source option for multi-modal data labeling workflows.
For production computer vision systems with teams: Paid data annotation tools—Roboflow, Encord, V7 Labs, Labelbox, or SuperAnnotate—offer meaningful workflow management, collaboration controls, and AI-assisted labeling that pays off at scale across all data types. Pilot with your actual data before signing a contract.
For very large or enterprise operations: Scale AI is the most established option for large-scale data annotation across complex sensor data and physical AI use cases, though pricing is opaque and workforce practices have faced scrutiny.
For reducing annotation cost: Invest in data curation before the data annotation process begins. Removing near-duplicates, filtering uninformative samples, and applying active learning can substantially reduce the volume of training data that needs to reach a human annotator. LightlyStudio is purpose-built for this workflow.
Have questions about selecting a data annotation workflow for your use case? Lightly's team works with computer vision teams across industries. Contact us to discuss your project.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


